Pipeline 활용하기
시작하면서#
이번장에서 파이프라인의 다양한 활용방법을 익히고, 이를 이용해 앞선 튜토리얼에서 만든 머신러닝 모델의 워크플로우를 구현해보겠습니다.
info
Goal#
- 파이프라인을 활용하여 모델 워크플로우 만들기
튜토리얼 모델에 파이프라인 적용하기#

이 이미지는 우리의 모델 API 서버에서 "Ankle boot"로 판단했던 이미지를 약간 회전시킨 이미지입니다.
과연 모델 API 서버는 이 이미지를 어떻게 판단할까요?

T-shirts 라고 판단합니다.
이제 우리 모델 API 서버는 이렇게 회전된 이미지도 잘 예측하는 모델 서버로 거듭나게 하려고 합니다.
이 과정을 머신러닝 워크플로우 시나리오처럼 주기적인 데이터의 공급에 의한 모델의 재학습, 그리고 모델의 최신화 순서로 진행해 보겠습니다.
Test dataset 생성#
test dataset을 Augmentation 된 데이터를 포함하여 5:5 비율로 구성하여 모델을 평가하도록 합니다. 아무래도 기존 모델의 정확도는 이전보다 훨씬 떨어질 겁니다. 그리고 기존 60,000개의 train dataset 에 회전된 이미지(augmentation 된 이미지)가 주기적으로 추가되도록 하겠습니다. 데이터가 저장되는 볼륨은 노트북에서 ./new_dataset 을 기준으로 저장하겠습니다.
먼저 test dataset을 변경해보겠습니다. 여기서 회전된 이미지의 생성은 keras.preprocessing.image에서 제공하는 ImageDataGenerator를 사용하겠습니다. data_augmentation.ipynb 라는 이름의 노트북을 생성합니다. 아래의 코드는 fashion mnist 데이터 중 test dataset의 절반을 ImageDataGenerator를 이용해 회전 이미지 데이터 셋을 만든 후 npz 포멧으로 저장합니다.
Data Augmentation
데이터 증강(Data Augmentation) : 튜토리얼에서 만든 머신러닝 모델을 실제 생활에서 사용하려면 훈련에 사용된 명확한 이미지들은 당연히 올바르게 맞출 수 있어합니다. 하지만 현실의 데이터는 훈련에 사용된 데이터처럼 항상 올바른 각도, 올바른 크기로 입력되지 않을 것입니다. 따라서 학습용 데이터를 일부러 왜곡(회전, 반전, 가리기, 유실 등)시키는 작업을 Data Augmentation 이라고 부릅니다.
# data_augmentation.ipynbimport osimport numpy as npimport tensorflow as tffrom tensorflow.keras.preprocessing.image import ImageDataGenerator
img_rows, img_cols = 28, 28 dataset_path = "./new_dataset/test" #데이터셋 저장 경로
mnist = tf.keras.datasets.fashion_mnist(x_train, y_train), (x_test, y_test) = mnist.load_data()x_test_reshaped = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
datagen = ImageDataGenerator(rotation_range=180)
rotated_test = datagen.flow(x_test_reshaped[:5000], y_test[:5000], batch_size=1)
x_rotated_test = []y_rotated_test = []
for i in range(len(rotated_test)): rotated = rotated_test.next() x_rotated_test.append(rotated[0].reshape(28, 28)) y_rotated_test.append(rotated[1])
x_rotated_test = np.array(x_rotated_test) new_x_test = np.append(x_test[:5000], x_rotated_test, axis=0)new_y_test = np.append(y_test[:5000], y_rotated_test)os.makedirs(dataset_path, exist_ok=True)np.savez(f"{dataset_path}/new_test.npz", y_test=new_y_test, x_test=new_x_test)코드를 실행하면 노트북의 볼륨에 ./new_dataset/test/new_test.npz 파일이 생성되는 것을 확인 할 수 있습니다.
모델 테스트 컴포넌트 - Pipeline Metrics#
이제 새로운 test dataset 으로 모델을 test(검증)하는 파이프라인 컴포넌트를 만들어 보겠습니다. 그리고 모델 관리를 위해 Experiment를 하나 만들겠습니다. 파이프라인에서는 컴포넌트의 실행 결과 등을 메트릭으로 출력하여 RUN 리스트에 노출시킬 수 있는 기능을 제공합니다. 이를 이용해 모델 검증후 나오는 validation accuracy와 loss를 RUN 리스트에 노출시킬 수 있습니다. Experiments 메뉴로 이동하여 tutorial_model이라는 새로운 Experiment를 만들겠습니다. 모델 test 파이프라인의 RUN은 tutorial_model Experiment안에서만 실행되야합니다.
Pipeline의 Experiment 탭에서 +Create experiment 버튼을 눌러 새 experiment를 생성합니다.
Next를 누르면 바로 Run 실행 메뉴가 나옵니다.
아직 실행할 파이프라인이 없기에 하단의 Skip this step 버튼을 이용하여 건너뜁니다.
model_test_pipeline 이라는 빈 노트북을 생성합니다. 베이스가 되는 모델을 정하기 위해서 fashion_mnist_serving.ipynb 노트북을 열어 MyModel 클래스를 가져와 새로운 셀에 옮깁니다. 그리고 model.fit을 한 후에 모델을 /model 디렉토리에 저장하도록 수정하겠습니다.
# model_test_pipeline.ipynbimport osimport datetimeimport tensorflow as tf import argparsefrom tensorflow.python.keras.callbacks import Callback
class MyModel(object): def __init__(self): self.model_path = None self.model = None def get_model_path(self): return self.model_path def get_model(self): return self.model def train(self): parser = argparse.ArgumentParser() parser.add_argument('--node_amount', required=False, type=int, default=128) parser.add_argument('--epoch', required=False, type=int, default=10) parser.add_argument('--dropout_rate', required=False, type=float, default=0.2) parser.add_argument('--optimizer', required=False, type=str, default="sgd") if os.getenv('FAIRING_RUNTIME', None) is None: args = parser.parse_args(args=[]) else: args = parser.parse_args() mnist = tf.keras.datasets.fashion_mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
print("x_train shape:", x_train.shape, "y_train shape:", y_train.shape) print("x_test shape:", x_test.shape, "y_test shape:", y_test.shape)
x_train, x_test = x_train / 255.0, x_test / 255.0
self.model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(args.node_amount, activation='relu'), tf.keras.layers.Dropout(args.dropout_rate), tf.keras.layers.Dense(10, activation='softmax') ])
self.model.compile(optimizer=args.optimizer, loss='sparse_categorical_crossentropy', metrics=['acc'])
date_folder = datetime.datetime.now().strftime("%Y%m%d-%H%M%S") if os.getenv('FAIRING_RUNTIME', None) is None: log_dir = "log/fit/" + date_folder else: log_dir = "/notebook/log/fit/" + date_folder
print(f"tensorboard log dir : {log_dir}")
tensorboard_cb = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1) print(f"Total epochs {args.epoch}") hist = self.model.fit(x_train, y_train, verbose=0, validation_data=(x_test, y_test), epochs=args.epoch, callbacks=[LoggingTrain(), tensorboard_cb]) model_ver = get_strftime('%Y%m%d%H%M%S') # timestamp 형식 변경 (문자 제거) model_val_acc = int(float(hist.history['val_acc'][-1]) * 100) # 소수점 제거 self.model_path = f"model/{model_ver}.{model_val_acc}" self.model.save(self.model_path, save_format='tf') return self.model def get_strftime(time_format): dt_now = datetime.datetime.now() return dt_now.strftime(time_format)
def p(msg): dt_now = datetime.datetime.now() strftime = dt_now.strftime('%Y-%m-%dT%H:%M:%SZ') print(f"{strftime} {msg}", flush=True) class LoggingTrain(Callback): """logging for train """ def on_batch_end(self, batch, logs={}): if batch % 100 == 0: p(f"batch: {batch}") p(f"accuracy={logs.get('acc')} loss={logs.get('loss')}") def on_epoch_begin(self, epoch, logs={}): p(f"epoch: {epoch}")
def on_epoch_end(self, epoch, logs={}): p(f"Validation-accuracy={logs.get('val_acc')}") p(f"Validation-loss={logs.get('val_loss')}") return 모델의 버전은 {timestamp}.{validation-accuracy}로 정의되며 ./model 폴더에 버전명으로 저장이 될 겁니다. 이제 학습을 진행시켜 모델을 저장합시다.
# model_test_pipeline.ipynbmy_model = MyModel()model = my_model.train()파이프라인의 모델 검증 컴포넌트는
- test dataset 로로
- 입력 받은 경로에서 모델 로드
- model 검증
- 메트릭 출력
의 순서로 수행됩니다.
메트릭을 출력하기 위해서는 리턴 타입을
# model_test_pipeline.ipynbNamedTuple('Outputs', [ ('mlpipeline_metrics', 'Metrics'),])로 정의한 후, 컴포넌트 함수에서
# model_test_pipeline.ipynb metrics = { 'metrics': [{ 'name': 'accuracy-score', # Run list 에서 보일 메트릭의 이름 'numberValue': accuracy, # 숫자형의 값만 됩니다. 'format': "PERCENTAGE", # value값의 포맷을 정합니다.. "RAW"/"PERCENTAGE" }] }
from collections import namedtuple result = namedtuple( 'Outputs', ['mlpipeline_metrics']) return result(json.dumps(metrics))
로 정의하면 됩니다. val-acc, val-loss, model-version 를 메트릭 값으로 출력하도록 해보겠습니다.
아래는 전체 코드입니다.
# model_test_pipeline.ipynbimport kfpfrom kfp import dslfrom kfp.components import func_to_container_opfrom typing import NamedTuple
def test_model_component(model_version: str) -> NamedTuple('Outputs', [ ('mlpipeline_metrics', 'Metrics'),]): import tensorflow as tf import numpy as np import json test_dataset = np.load("/notebook/new_dataset/test/new_test.npz") x_test = test_dataset['x_test'] y_test = test_dataset['y_test'] loaded_model = tf.keras.models.load_model(f"/notebook/model/{model_version}") score = loaded_model.evaluate(x_test, y_test, verbose=0) print(f"test-accuracy = {score[1]}, test-loss={score[0]}")
metrics = { 'metrics': [{ 'name': 'val-acc', 'numberValue': float(round(score[1], 4)), 'format': "PERCENTAGE", }, { 'name': 'val-loss', 'numberValue': float(round(score[0], 4)), 'format': "RAW", }, { 'name': 'model-version', 'numberValue': float(model_version), 'format': "RAW", }] } from collections import namedtuple result = namedtuple( 'Outputs', ['mlpipeline_metrics']) return result(json.dumps(metrics))
노트북의 test dataset과 모델의 경로는 /notebook 로 마운트 될 예정입니다.
이제 파이프라인 함수를 만들겠습니다. 컴포넌트에 쓸 베이스 이미지 설정과 노트북 볼륨 마운트 작업을 합니다.
단, create_component_from_func로 만들어진 컴포넌트는 볼륨을 추가할 수 없기 때문에 func_to_container_op 를 이용해 파이프라인 컴포넌트를 만들어야 합니다.
# model_test_pipeline.ipynbdef test_model_pipeline(model_version: str): test_model_op = func_to_container_op(test_model_component, base_image="dudaji/cap-jupyterlab:tf2.0-cpu") notebook_vol = dsl.PipelineVolume(pvc="workspace-handson") test_model = test_model_op(model_version) \ .add_pvolumes(pvolumes={"/notebook": notebook_vol}) test_model.execution_options.caching_strategy.max_cache_staleness = "P0D"
아래는 RUN으로 실행시키는 코드가 포함된 전체 코드 입니다. 실행시킬 때 experiment_name="tutorial_model" 를 정의해 특정 experiment로 RUN이 실행됩니다.
# model_test_pipeline.ipynbimport kfpfrom kfp import dslfrom kfp.components import func_to_container_op, OutputPathfrom typing import NamedTuple
def test_model_component(model_version: str) -> NamedTuple('Outputs', [ ('mlpipeline_metrics', 'Metrics'),]): import tensorflow as tf import numpy as np import json test_dataset = np.load("/notebook/new_dataset/test/new_test.npz") x_test = test_dataset['x_test'] y_test = test_dataset['y_test'] loaded_model = tf.keras.models.load_model(f"/notebook/model/{model_version}") score = loaded_model.evaluate(x_test, y_test, verbose=0) print(f"test-accuracy = {score[1]}, test-loss={score[0]}")
metrics = { 'metrics': [{ 'name': 'val-acc', 'numberValue': float(round(score[1], 4)), 'format': "PERCENTAGE", }, { 'name': 'val-loss', 'numberValue': float(round(score[0], 4)), 'format': "RAW", }, { 'name': 'model-version', 'numberValue': float(model_version), 'format': "RAW", }] } from collections import namedtuple result = namedtuple( 'Outputs', ['mlpipeline_metrics']) return result(json.dumps(metrics))
def test_model_pipeline(model_version: str): test_model_op = func_to_container_op(test_model_component, base_image="dudaji/cap-jupyterlab:tf2.0-cpu")
notebook_vol = dsl.PipelineVolume(pvc="workspace-handson") test_model = test_model_op(model_version) \ .add_pvolumes(pvolumes={"/notebook": notebook_vol}) test_model.execution_options.caching_strategy.max_cache_staleness = "P0D"
arguments = {'model_version': "20210730004535.85"} # MyModel을 학습시켜 나온 모델버전을 넣어주세요.
client = kfp.Client()client.create_run_from_pipeline_func(test_model_pipeline, experiment_name="tutorial_model", arguments=arguments) 
val-acc가 절반가까이 떨어진 것을 확인할 수 있습니다. 테스트 데이터의 절반이 새로운 데이터로 바뀌었기 때문입니다. 이제 컴파일 하여 파이프라인으로 등록해보겠습니다.
# model_test_pipeline.ipynbkfp.compiler.Compiler().compile(pipeline_func=test_model_pipeline, package_path='test_model_pipeline.yaml')
client.upload_pipeline(pipeline_name="test-model-pipeline", pipeline_package_path="test_model_pipeline.yaml")RAW 데이터 수집 파이프라인 - Recurring Run#
주기적으로 데이터를 공급하기위해 파이프라인의 Recurring Run을 이용하겠습니다.
test dataset과 마찬가지로 ImageDataGenerator를 활용하여 노트북의 ./new_dataset/raw 경로에 png 이미지를 생성합니다. 그리고 'collect_raw_data' Experiment에 Run을 실행하도록 합니다.
collect_data_pipeline.ipynb 노트북을 생성합니다. 데이터의 생성 로직은 test dataset을 만들때와 유사합니다. 한번 실행에 무작위로 회전된 100개의 이미지를 생성해보겠습니다.
# collect_data_pipeline.ipynbimport kfpfrom kfp import dslfrom kfp.components import func_to_container_opfrom typing import NamedTuple
def collect_data_component(gen_count: int = 100): import datetime import os from random import randint import tensorflow as tf from PIL import Image, ImageOps from tensorflow.keras.preprocessing.image import ImageDataGenerator
def save_image(filename, data_array): im = Image.fromarray(data_array.astype('uint8')) im_invert = ImageOps.invert(im) im_invert.save(filename)
img_rows, img_cols = 28, 28
mnist = tf.keras.datasets.fashion_mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train_reshaped = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
datagen = ImageDataGenerator(rotation_range=180)
pick_index = randint(1, len(x_train) / gen_count) start = (pick_index - 1) * gen_count end = pick_index * gen_count rotated_train = datagen.flow(x_train_reshaped[start:end], y_train[start:end], batch_size=1) raw_path = "/notebook/new_dataset/raw" date_postfix = datetime.datetime.now().strftime("%Y%m%d%H%M%S") os.makedirs(raw_path, exist_ok=True) for i in range(len(rotated_train)): rotated = rotated_train.next() filename = f"{raw_path}/{rotated[1][0]}-{date_postfix}{i}.png" save_image(filename, rotated[0].reshape(img_rows, img_cols))
이미지는 {label}-{생성일시}{gen_index}.png 이름으로 저장이 됩니다.
아래는 파이프라인 함수입니다. model_test_pipeline 함수와 마찬가지로 func_to_container_op 함수가 사용됩니다. 이전 파이프라인과 동일하게 베이스 이미지와 볼륨이 마운트됩니다.
# collect_data_pipeline.ipynbdef collect_data_pipeline(gen_count: int): collect_data_op = func_to_container_op(collect_data_component, base_image="dudaji/cap-jupyterlab:tf2.0-cpu")
notebook_vol = dsl.PipelineVolume(pvc="workspace-handson") collect_data = collect_data_op(gen_count) \ .add_pvolumes(pvolumes={"/notebook": notebook_vol}) collect_data.execution_options.caching_strategy.max_cache_staleness = "P0D" arguments = {"gen_count": 100}
client = kfp.Client()client.create_run_from_pipeline_func(collect_data_pipeline, experiment_name="collect_raw_data", arguments=arguments) 파이프라인 함수를 RUN 으로 실행하면 노트북의 ./new_dataset/raw 에 100개의 무작위로 회전된 fashion mnist 이미지가 생성됩니다.
이제 파이프라인으로 등록하여 10분마다 100개씩 데이터를 증강(Augmentation)하는 Recurring Run 으로 만들어 보겠습니다.
# collect_data_pipeline.ipynbkfp.compiler.Compiler().compile( pipeline_func=collect_data_pipeline, package_path='collect_data_pipeline.yaml')
client.upload_pipeline(pipeline_name="collect_data_pipeline", description="Collect new image", pipeline_package_path="collect_data_pipeline.yaml")Recurring Run을 만드는 방법은 2가지입니다.
- SDK의 kfp.Client().create_recurring_run()를 이용
- Pipeline UI의 Run 생성시 설정
컨텍스트 전환에 대한 부담을 줄이려면 SDK를 사용하는 것이 맞지만, 튜토리얼에서는 Pipeline UI로 등록하겠습니다.
방금 등록한 collect_data_pipeline의 Create run 버튼울 누릅니다.
Experiment 는 collect_raw_data를 설정합니다.
Run Type을 Recurring을 선택하면, Recurring run을 만들 수 있습니다.
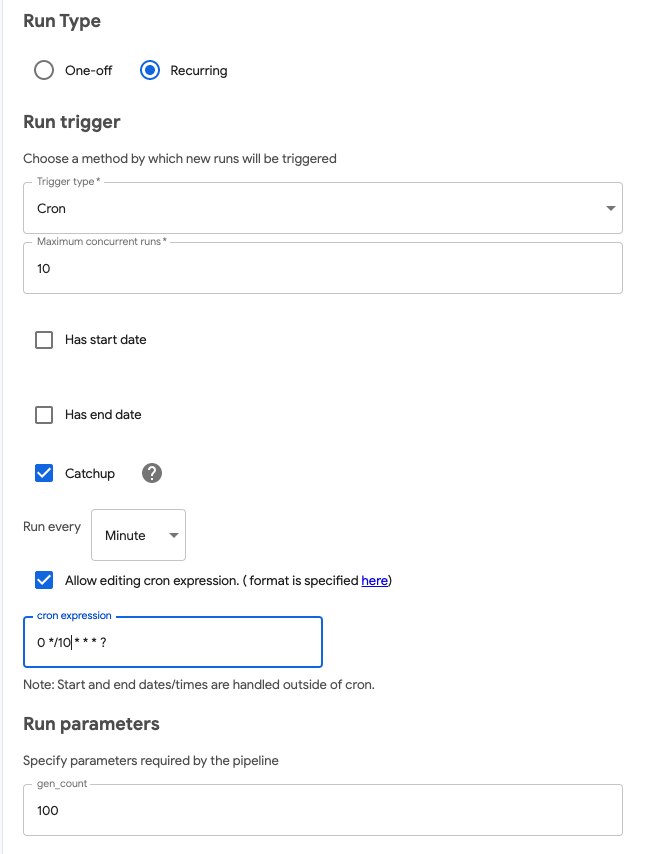
새로운 Run이 생성되는 트리거 타입을 Cron으로 설정합니다. 그리고 0, 10, 20, 30, 40, 50분 정각마다 실행될 수 있도록 cron expression에서 0 */10 * * * ?으로 설정합니다.
cron expression
0 */10 * * * ?
초 분 시 일 월 요일 연도(optional)
*: 매 번
?: 설정값 없음
/ : 값 증가
마지막으로 한번에 Run parameters에서 생성될 이미지 갯수를 입력합니다.
100개씩 회전된 이미지를 생성하여 추가 할 것이기에 gen_count 란에 100을 입력합니다.
작성이 완료되면 Start 버튼을 눌러서 Recurring run을 실행합니다.
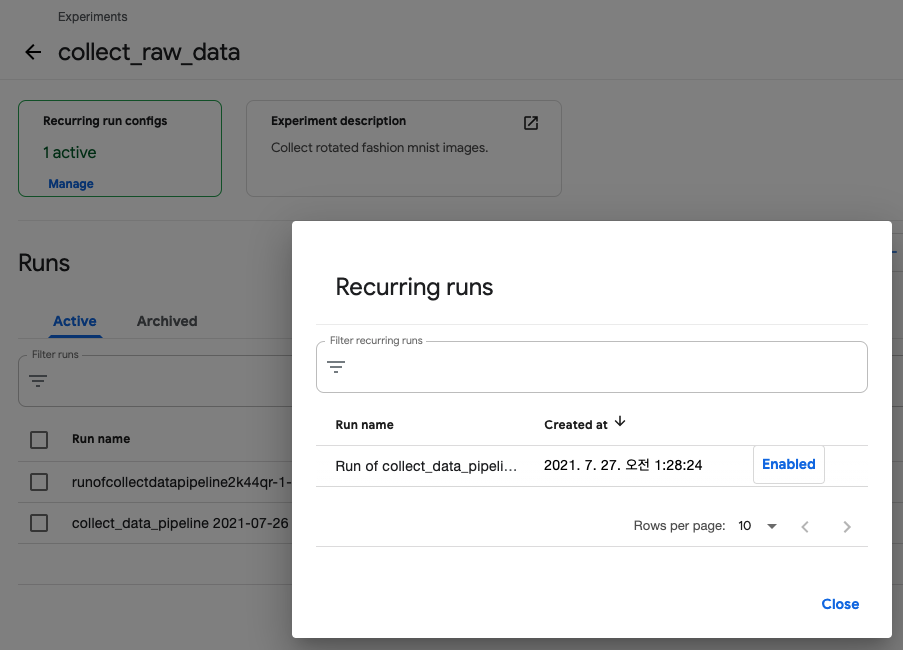
정상적으로 실행되면, 좌측 상단에 Active 되어 있는 Recurring run의 수를 확인할 수 있습니다.
Manage 버튼을 누르면 상세 정보와 Enable/disable 을 설정할 수 있는 팝업창이 뜹니다.
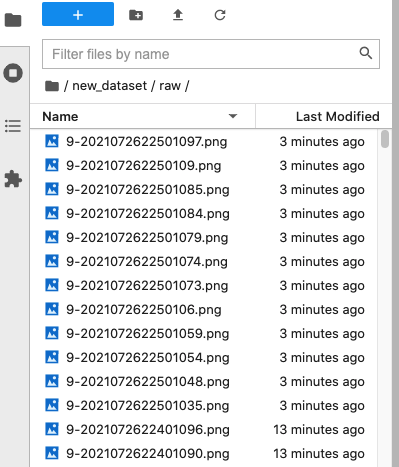
일정 시간이 지나고 노트북의 /new_dataset/raw 에 10분 간격으로 이미지가 생성되는 것을 확인합니다.
전처리 파이프라인 - Condition#
note
fashion mnist 데이터셋은 이미 전처리된 데이터셋이기에 정규화 외의 작업이 필요없습니다.
따라서 추가하고 있는 새로운 데이터에 대해서만 전처리를 진행합니다.
RAW 데이터 수집 컴포넌트에서 새로운 이미지가 100개씩 수집됩니다. 100개씩 추가될 때마다 모델을 재학습시키기에는 양이 적습니다.
그래서 새로운 이미지가 누적되어 1,000개가 될 때 이를 모아 npz 파일로 만듭니다. preprocessed_data라는 Experiment로 사용하겠습니다.
튜토리얼 진행을 위해 preprocess_data_pipeline.ipynb 라는 노트북을 생성합니다.
먼저 /new_dataset/raw의 파일개수를 count하여 output을 그 결과로 반환하는 컴포넌트 함수를 만듭니다.
# preprocess_data_pipeline.ipynbdef count_raw_images(raw_path: str) -> int: import fnmatch import os return len(fnmatch.filter(os.listdir(raw_path), '*.png'))그 다음 ./new_dataset/raw에서 생성순서가 가장 최근인 png 파일부터 요청된 개수만큼 npz 학습용 데이터셋을 만들어 저장 한 후, 그 저장된 경로를 반환하는 컴포넌트 함수를 만듭니다.
# preprocess_data_pipeline.ipynbdef preprocess_raw_images(raw_path: str, save_path: str, size: int = 1000) -> int: import datetime import fnmatch import numpy as np import os from PIL import Image
img_rows, img_cols = 28, 28
files = fnmatch.filter(os.listdir(raw_path), '*.png') files.sort(key=lambda fn: os.path.getmtime(os.path.join(raw_path, fn))) target_files = files[:size].copy()
x_train = [] y_train = [] for i, name in enumerate(target_files): img = Image.open(os.path.join(raw_path, name)) img_array = np.array(img) x_train.append(img_array.reshape(img_rows, img_cols)) y_train.append(int(name[0]))
x_train = np.array(x_train) # Save numpy arr to npz date_postfix = datetime.datetime.now().strftime("%Y%m%d%H%M%S") os.makedirs(save_path, exist_ok=True) npz_name = f"{date_postfix}-{size}.npz" npz_save_path = f"{save_path}/{npz_name}" np.savez(npz_save_path, x_train=x_train, y_train=y_train) # delete image for i, name in enumerate(target_files): file_path = os.path.join(raw_path, name) if os.path.isfile(file_path): os.remove(file_path) return npz_save_pathnpz파일이 생성되면 사용된 raw image는 삭제됩니다.
# preprocess_data_pipeline.ipynbprint(preprocess_raw_images("new_dataset/raw", "new_dataset/train")) 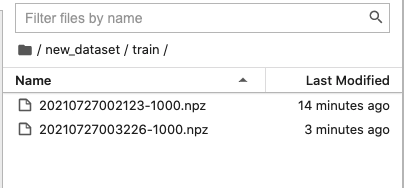
코드를 실행하면 new_dataset/train 폴더에 npz 파일이 생성됩니다.
이제 함수를 파이프라인으로 구성하겠습니다. 베이스 이미지는 기본으로 적용을 하고 preprocess_raw_images 함수가 pillow, numpy 를 사용하기 때문에 func_to_container_op 실행시 패키지 인스톨을 진행해야합니다. packages_to_install=["numpy", "pillow"] 를 파라미터로 넣게 되면 컴포넌트가 실행되기 전에 설치를 진행합니다. 이전 단계와 마찬가지로 데이터셋의 경로는 /notebook 에 노트북의 볼륨을 마운트하겠습니다.
패키지 인스톨
매 컴포넌트 실행마다 사용할 라이브러리를 설치하지 않으려면 해당 패키지가 이미 포함된 베이스 이미지를 사용하는게 좋습니다.
# preprocess_data_pipeline.ipynbimport kfpfrom kfp import dslfrom kfp.components import func_to_container_op
def disable_cache(op): op.execution_options.caching_strategy.max_cache_staleness = "P0D"
def preprocess_data_pipeline(raw_path: str = "/notebook/new_dataset/raw", save_path: str = "/notebook/new_dataset/train", size: int = 1000): notebook_vol = dsl.PipelineVolume(pvc="workspace-handson") count_op = func_to_container_op(count_raw_images) preprocess_op = func_to_container_op(preprocess_raw_images, packages_to_install=["numpy", "pillow"]) count = count_op(raw_path).add_pvolumes(pvolumes={"/notebook": notebook_vol}) disable_cache(count) with dsl.Condition(count.output > size): preprocess = preprocess_op(raw_path, save_path, size) \ .add_pvolumes(pvolumes={"/notebook": notebook_vol}) disable_cache(preprocess)count_op 에서 나온 결과값이 1000이 넘으면 preprocess_op 가 실행되는 구조입니다. 이제 RUN 으로 실행해봅시다. preprocessed_data Experiment 에서 실행합니다.
# preprocess_data_pipeline.ipynbarguments = {"raw_path": "/notebook/new_dataset/raw", "save_path": "/notebook/new_dataset/train"}
client = kfp.Client()client.create_run_from_pipeline_func(preprocess_data_pipeline, experiment_name="preprocessed_data", arguments=arguments) 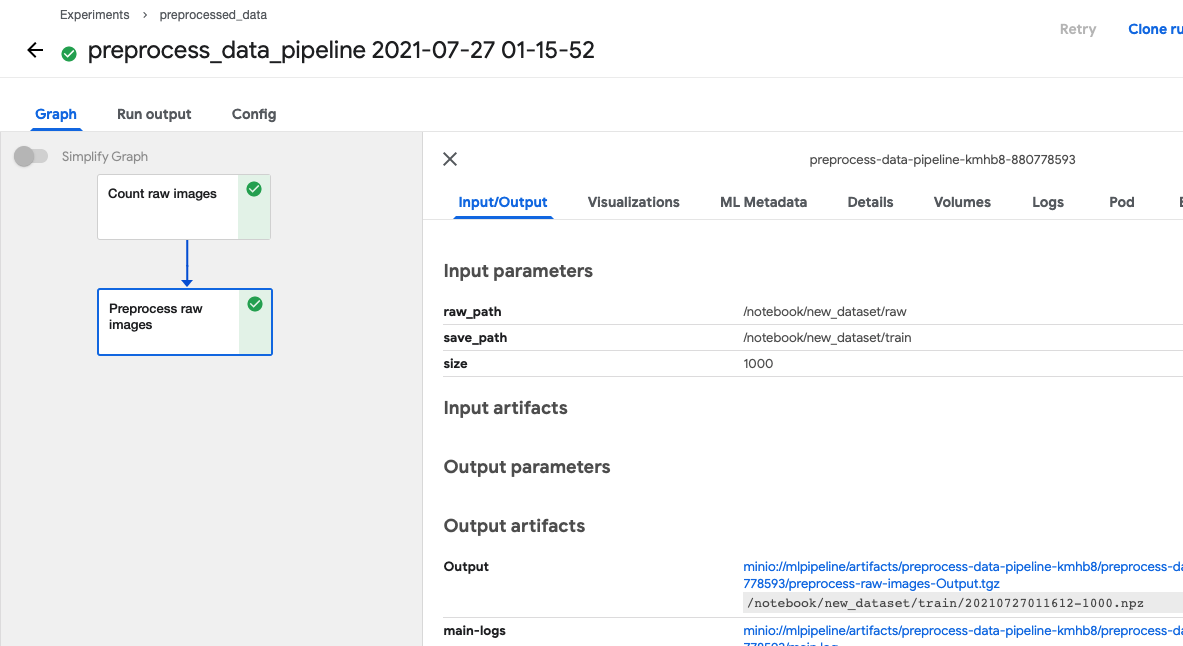
이제 파이프라인으로 등록한 후, Recurring Run 으로 Raw images를 데이터셋으로 만들어보겠습니다.
new_dataset/raw 의 파일 수를 체크하기 때문에 기존 collect_data_pipeline 과 겹치지 않게 5, 35분 간격으로 설정하겠습니다.
CRON EXPRESSION : 0 5,35 * * * ?
# preprocess_data_pipeline.ipynbkfp.compiler.Compiler().compile( pipeline_func=preprocess_data_pipeline, package_path='preprocess_data_pipeline.yaml')
client.upload_pipeline(pipeline_name="preprocess_data_pipeline", description="Convert raw images to npz", pipeline_package_path="preprocess_data_pipeline.yaml") 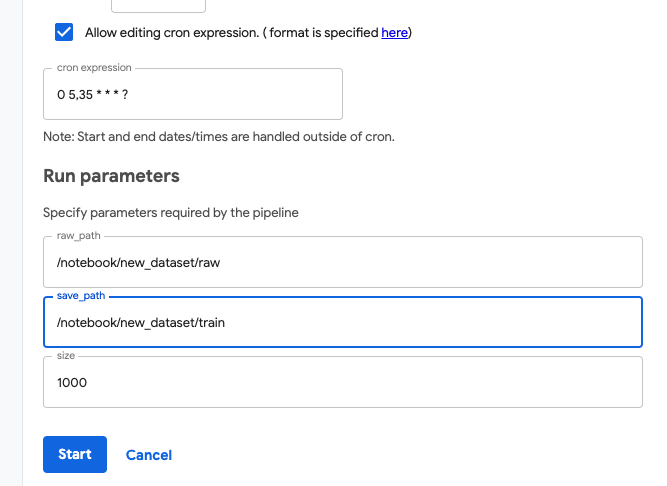
note
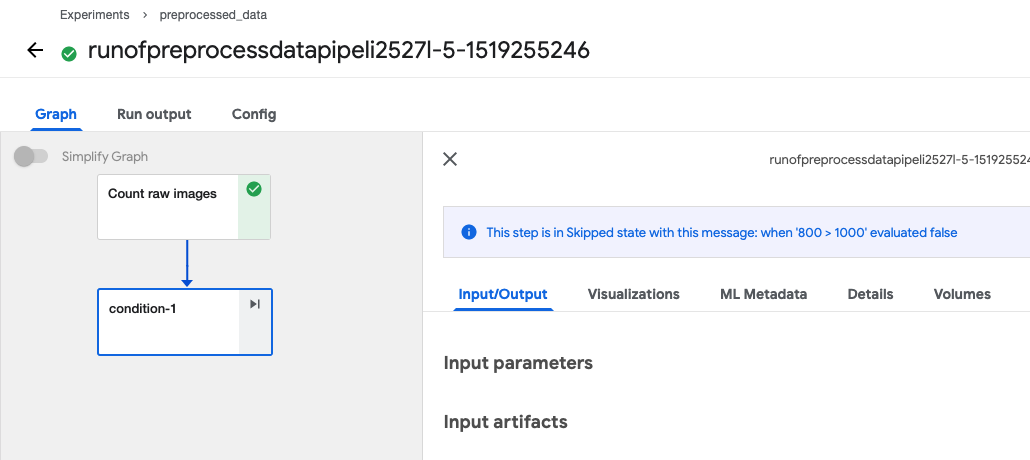
new_dataset/raw 에 있는 이미지가 1000개가 되지 않을 경우
아래와 같이 다음 단계의 컴포넌트는 실행하지 않습니다.
재학습 파이프라인 with Tuner#
앞 단계에서 생성된 새로운 데이터셋을 가지고 학습을 진행하는 파이프라인을 만들어 보겠습니다. 기존 tutorial_model experiment에서 가장 높은 val-acc를 기록한 모델을 불러와 재학습을 진행합니다.
기존 데이터셋과 새로운 데이터셋을 합쳐서 재학습을 진행하며 Tuner에서 추가된 데이터셋에 맞는 모델의 하이퍼파라미터 튜닝을 진행하겠습니다. 새로운 데이터셋은 ./new_dataset/train 에서 가장 오래된 npz파일을 가져와 학습을 진행하며, 학습이 완료되면 ./new_dataset/retrain 폴더로 npz 데이터셋을 옮기겠습니다.
이 컴포넌트는 train_model Experiment에서 실행이 됩니다.
train_pipeline.ipynb 라는 새 노트북을 생성합니다.
get_best_model 컴포넌트#
get_best_model 컴포넌트를 만들어 val-acc 가 가장 높은 모델을 가져와보겠습니다.
# train_pipeline.ipynb
from typing import NamedTuple
def get_best_model(goal_acc: float = 0.40, experiment_name: str = "tutorial_model") \ -> NamedTuple('BestModel', [('version', float), ('acc', float)]): import kfp import os
os.environ["KF_PIPELINES_ENDPOINT"] = "http://ml-pipeline.kubeflow.svc.cluster.local:8888"
kfp_proxy_host = os.environ["KFP_PROXY_SERVICE_HOST"] kfp_proxy_port = os.environ["KFP_PROXY_SERVICE_PORT"]
client = kfp.Client(proxy=f"http://{kfp_proxy_host}:{kfp_proxy_port}") #client = kfp.Client()
experiment = client.get_experiment(experiment_name=experiment_name) list_runs = client.list_runs(experiment_id=experiment.id, page_size=0) runs = list_runs.runs
best_model = {'path': 'None', 'acc': goal_acc} for run in runs:
run_dict = run.to_dict() if run_dict['storage_state'] == 'STORAGESTATE_ARCHIVED': continue if run_dict['metrics'] is None: continue if run_dict['status'] != 'Succeeded': continue if run_dict['pipeline_spec']['parameters'] is None: continue model = {'version': run_dict['metrics'][0]['number_value'], 'acc': run_dict['metrics'][1]['number_value']} if best_model['acc'] < model['acc']: best_model = model print(best_model)
from collections import namedtuple result = namedtuple('BestModel', ['version', 'acc'])
return result(best_model['version'], best_model['acc'])
코드 설명
pipeline client
# TODO init pieline endpointos.environ["KF_PIPELINES_ENDPOINT"] = "http://ml-pipeline.kubeflow.svc.cluster.local:8888"kfp_proxy_host = os.environ["KFP_PROXY_SERVICE_HOST"]kfp_proxy_port = os.environ["KFP_PROXY_SERVICE_PORT"]client = kfp.Client(proxy=f"http://{kfp_proxy_host}:{kfp_proxy_port}")파이프라인 클라이언트를 사용하기 위한 설정입니다. 파이프라인 API를 사용려면 인증을 거쳐야 하는데
그 인증 역할을 해주는 프록시 서버를 kfp 클라이언트에 정의 합니다.
experiment, list_runs
experiment = client.get_experiment(experiment_name=experiment_name) list_runs = client.list_runs(experiment_id=experiment.id, page_size=0)여기서 list_runs()는 ApiListRunsResponse 클래스를 반환합니다. 이 클래스는 Run 리스트의 정보를 보여줍니다.
run check
if run_dict['storage_state'] == 'STORAGESTATE_ARCHIVED': continue if run_dict['metrics'] is None: continue if run_dict['status'] != 'Succeeded': continue if run_dict['pipeline_spec']['parameters'] is None: continue run 중에 정상적이지 않은 항목은 제외합니다.
get metric
model = {'version': run_dict['metrics'][0]['number_value'], 'acc': run_dict['metrics'][1]['number_value']}RUN의 메트릭을 가져옵니다. index 0은 version을 의미하며, index 1은 acc를 의미합니다.
get_last_dataset 컴포넌트#
재학습에 쓰일 데이터셋을 가져오는 get_last_dataset 컴포넌트를 작성합니다.
def get_last_dataset(data_path: str) -> str: import fnmatch import numpy as np import os files = fnmatch.filter(os.listdir(data_path), '*.npz') files.sort(key=lambda fn: os.path.getmtime(os.path.join(data_path, fn))) return os.path.join(data_path, files[1])./notebook/train에 저장된 npz 파일중 제일 오래된 파일의 경로를 반환합니다.
tip
가장 오래된 npz파일을 가져오는건, 가장 먼저 들어온 데이터셋부터 포함시켜 재학습 시키기 위함입니다. 파이프라인 워크플로우 흐름이 한번 끝날때 마다 모델과 데이터셋이 업데이트됩니다.
MyModel 수정 - AppendBuilder#
학습을 진행하는 컴포넌트를 작성하기 전에 model_test_pipeline.ipynb 노트북에서 사용한
MyModel 클래스가 데이터셋과 모델을 입력받을 수 있게 수정하겠습니다.
my_model_retrain.ipynb 라는 빈 노트북을 하나 생성합니다. 그리고 MyModel 클래스를 옮겨옵니다.
아래는 수정/추가된 부분의 코드입니다. 기존의 MyModel에 새로운 데이터셋 경로와 이미 학습된 모델의 경로가 존재하면 기존 데이터셋에 추가 후 이미 학습된 모델로 학습을 진행합니다. 그리고 모델 저장 버전을 입력받을 수 있게 추가합니다.
# model_test_pipeline.ipynbimport osimport datetimeimport tensorflow as tf import argparsefrom tensorflow.python.keras.callbacks import Callback
class MyModel(object): def __init__(self): self.model_path = None self.model = None def get_model_path(self): return self.model_path def get_model(self): return self.model def train(self): parser = argparse.ArgumentParser() parser.add_argument('--node_amount', required=False, type=int, default=128) parser.add_argument('--epoch', required=False, type=int, default=10) parser.add_argument('--dropout_rate', required=False, type=float, default=0.2) parser.add_argument('--optimizer', required=False, type=str, default="sgd") parser.add_argument('--dataset_path', required=False, type=str, default=None) parser.add_argument('--model_path', required=False, type=str, default=None) parser.add_argument('--train_version', required=False, type=str, default=None) parser.add_argument('--save_version', required=False, type=str, default=None)
mnist = tf.keras.datasets.fashion_mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
print("x_train shape:", x_train.shape, "y_train shape:", y_train.shape) print("x_test shape:", x_test.shape, "y_test shape:", y_test.shape)
if os.getenv('FAIRING_RUNTIME', None) is None: args = parser.parse_args(args=[]) else: args = parser.parse_args() if args.dataset_path is not None: new_dataset = np.load(args.dataset_path) new_x = new_dataset['x_train'] new_y = new_dataset['y_train']
add_x_train, add_x_test, \ add_y_train, add_y_test = train_test_split(new_x, new_y, test_size=0.1, random_state=42) train_size = len(add_y_train) test_size = len(add_y_test) x_train = np.append(x_train[:train_size], add_x_train, axis=0) x_test = np.append(x_test[:test_size], add_x_test, axis=0) y_train = np.append(y_train[:train_size], add_y_train, axis=0) y_test = np.append(y_test[:test_size], add_y_test, axis=0) if args.model_path is None: self.model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(args.node_amount, activation='relu'), tf.keras.layers.Dropout(args.dropout_rate), tf.keras.layers.Dense(10, activation='softmax') ])
self.model.compile(optimizer=args.optimizer, loss='sparse_categorical_crossentropy', metrics=['acc']) else: self.model = tf.keras.models.load_model(args.model_path)
x_train, x_test = x_train / 255.0, x_test / 255.0
self.model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(args.node_amount, activation='relu'), tf.keras.layers.Dropout(args.dropout_rate), tf.keras.layers.Dense(10, activation='softmax') ])
self.model.compile(optimizer=args.optimizer, loss='sparse_categorical_crossentropy', metrics=['acc'])
date_folder = datetime.datetime.now().strftime("%Y%m%d-%H%M%S") if os.getenv('FAIRING_RUNTIME', None) is None: log_dir = "log/fit/" + date_folder else: log_dir = "/notebook/log/fit/" + date_folder
print(f"tensorboard log dir : {log_dir}")
tensorboard_cb = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1) print(f"Total epochs {args.epoch}") hist = self.model.fit(x_train, y_train, verbose=0, validation_data=(x_test, y_test), epochs=args.epoch, callbacks=[LoggingTrain(), tensorboard_cb]) model_ver = get_strftime('%Y%m%d%H%M%S') # timestamp 형식 변경 (문자 제거) if args.save_version is None: model_ver = get_strftime('%Y%m%d%H%M%S') else: model_ver = args.save_version model_val_acc = int(float(hist.history['val_acc'][-1]) * 100) self.model_version = f"{model_ver}.{model_val_acc}" save_model_path = f"{args.model_path}/{self.model_version}" self.model.save(save_model_path, save_format='tf') return self.model def get_strftime(time_format): dt_now = datetime.datetime.now() return dt_now.strftime(time_format)
def p(msg): dt_now = datetime.datetime.now() strftime = dt_now.strftime('%Y-%m-%dT%H:%M:%SZ') print(f"{strftime} {msg}", flush=True) class LoggingTrain(Callback): """logging for train """ def on_batch_end(self, batch, logs={}): if batch % 100 == 0: p(f"batch: {batch}") p(f"accuracy={logs.get('acc')} loss={logs.get('loss')}") def on_epoch_begin(self, epoch, logs={}): p(f"epoch: {epoch}")
def on_epoch_end(self, epoch, logs={}): p(f"Validation-accuracy={logs.get('val_acc')}") p(f"Validation-loss={logs.get('val_loss')}") return 수정이 완료되면 Tuner에 사용하기 위해 fairing 을 이용해 컨테이너 이미지로 만들어줍니다.
import osfrom kubeflow.fairing.builders.append.append import AppendBuilderfrom kubeflow.fairing.preprocessors.converted_notebook import ConvertNotebookPreprocessor
if __name__ == '__main__': if os.getenv('FAIRING_RUNTIME', None) is None: preprocessor = ConvertNotebookPreprocessor(notebook_file="my_model_retrain.ipynb")
DOCKER_REGISTRY = "yourID" # 도커허브 아이디 base_image = "dudaji/cap-jupyterlab:tf2.0-cpu" image_name = "fashion-mnist-retrain" image_tag = "handson"
builder = AppendBuilder(registry=DOCKER_REGISTRY, image_name=image_name, base_image=base_image, tag=image_tag, preprocessor=preprocessor, push=True) image_name = builder.build() print(image_name)
else: remote_model = MyModel() remote_model.train()모델 서빙하기에서 ClusterBuilder 클래스를 사용했습니다. 여기서는 AppendBuilder를 사용하여 컨테이너 이미지를 빌드합니다. ConvertNotebookPreprocessor preprocessor 를 사용하여 노트북 전체를 컨테이너 이미지로 빌드합니다. 실행 후 이미지 이름을 확인합시다.
train_from_best_model 컴포넌트 with Tuner#
다시 train_pipeline.ipynb 노트북으로 돌아와서 입력받은 모델으로 Tuner를 실행시키는 train_from_best_model 컴포넌트를 만들어 봅시다.
새로운 셀을 추가하고 Tuner SDK를 사용하는 아래 코드를 붙여넣습니다.
important
아래 코드를 붙여 넣을때, 이미지 이름을 바꾸어 주세요 (yourID)
# train_pipeline.ipynb
from typing import NamedTuple
def train_from_best_model(model_version: float, new_dataset_path: str) \ -> NamedTuple('Outputs', [('mlpipeline_metrics', 'Metrics'), ('model_version', float)]): import datetime import time import json import os import shutil from kubeflow import katib from kubeflow.katib import KatibClient
from kubernetes.client import V1ObjectMeta from kubeflow.katib import V1beta1Experiment from kubeflow.katib import V1beta1AlgorithmSpec from kubeflow.katib import V1beta1ObjectiveSpec from kubeflow.katib import V1beta1FeasibleSpace from kubeflow.katib import V1beta1ExperimentSpec from kubeflow.katib import V1beta1ObjectiveSpec from kubeflow.katib import V1beta1ParameterSpec from kubeflow.katib import V1beta1TrialTemplate from kubeflow.katib import V1beta1TrialParameterSpec
def find_metrics(_list, name, _type): return next(filter(lambda _list: _list['name'] == name, _list))[_type] def move_dataset(orig_path): target_dir = "/notebook/new_dataset/retrain" os.makedirs(target_dir, exist_ok=True) npz = os.path.basename(orig_path) shutil.copy(orig_path, f'{target_dir}/{npz}')
kclient = KatibClient() kclient.list_experiments() date_postfix = datetime.datetime.now().strftime("%Y%m%d%H%M%S") experiment_name = f"my-model-retrain-{date_postfix}" objective_metric_name = "Validation-accuracy"
metadata = V1ObjectMeta( name=experiment_name )
algorithm_spec = V1beta1AlgorithmSpec( algorithm_name="random" )
objective_spec = V1beta1ObjectiveSpec( type="maximize", goal=0.99, objective_metric_name=objective_metric_name, additional_metric_names=["Validation-loss", "accuracy", "loss"] )
parameters = [ V1beta1ParameterSpec( name="epoch", parameter_type="int", feasible_space=V1beta1FeasibleSpace( min="10", max="30" ), ), ]
dt_now = datetime.datetime.now() save_version = dt_now.strftime('%Y%m%d%H%M%S') # JSON template specification for the Trial's Worker Kubernetes Job. trial_spec = { "apiVersion": "batch/v1", "kind": "Job", "spec": { "template": { "metadata": { "annotations": { "sidecar.istio.io/inject": "false" } }, "spec": { "containers": [ { "name": "training-container", "image": "yourID/fashion-mnist-retrain:handson", "imagePullPolicy": "Always", "volumeMounts": [ {"name": "notebook", "mountPath": "/notebook"}, ], "command": [ "python", "/app/my_model_retrain.py", "--node_amount=${trialParameters.epoch}", f"--dataset_path={new_dataset_path}", f"--model_path=/notebook/model/", f"--train_version={model_version}", f"--save_version={save_version}" ] } ], "restartPolicy": "Never", "volumes": [ {"name": "notebook", "persistentVolumeClaim": {"claimName": "workspace-handson"} } ] } } } }
# Configure parameters for the Trial template. trial_template = V1beta1TrialTemplate( primary_container_name="training-container", trial_parameters=[ V1beta1TrialParameterSpec( name="epoch", description="train epoch", reference="epoch" ), ], trial_spec=trial_spec )
# Experiment object. experiment = V1beta1Experiment( api_version="kubeflow.org/v1beta1", kind="Experiment", metadata=metadata, spec=V1beta1ExperimentSpec( max_trial_count=3, parallel_trial_count=3, max_failed_trial_count=3, algorithm=algorithm_spec, objective=objective_spec, resume_policy=None, parameters=parameters, resume_policy=None, trial_template=trial_template, ) ) kclient.create_experiment(experiment) accuracy = 0.0 while 1: time.sleep(60) status = kclient.get_experiment_status(experiment_name) result = kclient.get_optimal_hyperparameters(experiment_name) if status == "Running": print(f"{experiment_name} is running") if status == "Succeeded": if result: metrics = result['currentOptimalTrial']['observation']['metrics'] val_acc = find_metrics(metrics, objective_metric_name, 'max') move_dataset(new_dataset_path) break
metrics = { 'metrics': [{ 'name': 'val-acc', 'numberValue': float(val_acc), 'format': "PERCENTAGE", },{ 'name': 'model-version', 'numberValue': float(save_version) + float(val_acc[:4]), 'format': "RAW", }] } from collections import namedtuple result = namedtuple('Outputs', ['mlpipeline_metrics', 'model_version']) return result(json.dumps(metrics), model_version) 코드 설명
def train_from_best_model(model_version: float, new_dataset_path: str) \ -> NamedTuple('Outputs', [('mlpipeline_metrics', 'Metrics'), ('model_version', str)]): ... (중략) ... metrics = { 'metrics': [{ 'name': 'val-acc', 'numberValue': float(accuracy), 'format': "PERCENTAGE", }] } from collections import namedtuple result = namedtuple('Outputs', ['mlpipeline_metrics', 'model_version']) return result(json.dumps(metrics), model_version) 학습 후 validation_accuracy의 값을 val-acc라는 Metric으로 반환합니다.
(중략) ... trial_spec = { "apiVersion": "batch/v1", "kind": "Job", ... (중략) ... "volumeMounts": [ {"name": "notebook", "mountPath": "/notebook"}, ], ... (중략) ... "volumes": [ {"name": "notebook", "persistentVolumeClaim": {"claimName": "workspace-handson"} } ] 학습이 진행될 때 데이터셋과 모델을 로드하기 위해 노트북 볼륨을 trial_spec에 마운트하게 정의합니다.
status = kclient.get_experiment_status(experiment_name) result = kclient.get_optimal_hyperparameters(experiment_name) ... (중략) ... if result: metrics = result['currentOptimalTrial']['observation']['metrics'] val_acc = find_metrics(metrics, objective_metric_name, 'max') breaksdk를 이용해 현재 상태와 현재 최고의 값를 내고 있는 학습에 대한 상세 정보를 알 수 있습니다.
train_pipeline 파이프라인 함수 만들기#
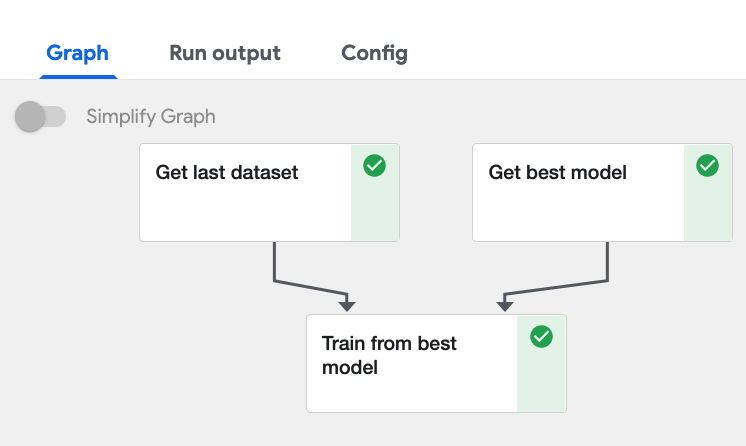
새로운 셀을 추가하고 train_pipeline 라는 파이프라인 함수를 만들겠습니다. 총 3개의 컴포넌트를 연결합니다. 베스트 모델과 새로운 데이터의 입력을 동시에 받는 구조입니다.
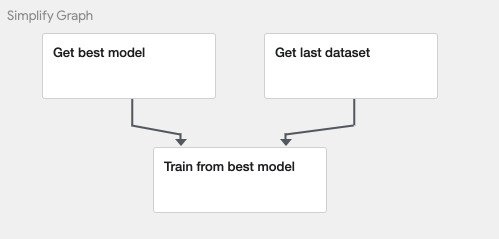
# train_pipeline.ipynb
from kfp import dslfrom kfp.components import func_to_container_op
def disable_cache(op): op.execution_options.caching_strategy.max_cache_staleness = "P0D"
def container_op(func): return func_to_container_op(func, base_image="dudaji/cap-jupyterlab:tf2.0-cpu")
def train_pipeline(goal_acc: float = 0.40, dataset_path: str = "/notebook/new_dataset/train"): notebook_vol = dsl.PipelineVolume(pvc="workspace-handson")
model_op = container_op(get_best_model) dataset_op = container_op(get_last_dataset) train_op = container_op(train_from_best_model)
model_comp = model_op(goal_acc) \ .add_pvolumes(pvolumes={"/notebook": notebook_vol})
dataset_comp = dataset_op(dataset_path) \ .add_pvolumes(pvolumes={"/notebook": notebook_vol})
train_comp = train_op(model_version=model_comp.outputs['version'], new_dataset_path=dataset_comp.output) \ .add_pvolumes(pvolumes={"/notebook": notebook_vol}) disable_cache(dataset_comp) disable_cache(model_comp) disable_cache(train_comp)코드 설명
train_comp = train_op(trained_model_path=model_comp.outputs['path']get_best_model은 리턴값이 2개이기 때문에 outputs['path'] 형태로 값을 가져옵니다.
이제 파이프라인 함수를 RUN으로 생성합니다. train_model experiment에서 실행되도록 정의합니다.
arguments = {"goal_acc": 0.40, "dataset_path": "/notebook/new_dataset/train"}
client = kfp.Client()client.create_run_from_pipeline_func(train_pipeline, experiment_name="train_model", arguments=arguments) 정상적으로 실행이 되었다면, 아래와 같이 train_model experiment에서 실행된 RUN을 확인할 수 있습니다.

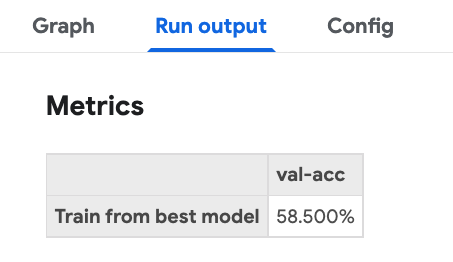
이제 파이프라인으로 등록하고 매시 정각에 학습하도록 Recurring run을 설정하겠습니다.
kfp.compiler.Compiler().compile(pipeline_func=train_pipeline, package_path='train_pipeline.yaml')client.upload_pipeline(pipeline_name="train_pipeline", description="Train from best model", pipeline_package_path="train_pipeline.yaml")experiment는 train_model 입니다.
매시 정각이기 때문에 Cron을 Trigger 타입으로 선택후 0 0 * * * ?** 를 입력합니다.
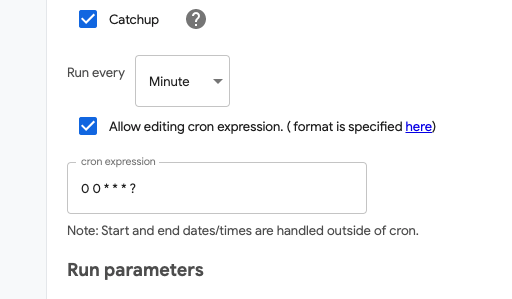
이제 매시 정각마다 재학습이 진행됩니다.
아래는 전체 코드 입니다.
# train_pipeline.ipynb
import kfpfrom kfp import dslfrom kfp.components import func_to_container_opfrom typing import NamedTuple
def get_best_model(goal_acc: float = 0.40, experiment_name: str = "tutorial_model") \ -> NamedTuple('BestModel', [('version', float), ('acc', float)]): import kfp import os
os.environ["KF_PIPELINES_ENDPOINT"] = "http://ml-pipeline.kubeflow.svc.cluster.local:8888"
kfp_proxy_host = os.environ["KFP_PROXY_SERVICE_HOST"] kfp_proxy_port = os.environ["KFP_PROXY_SERVICE_PORT"]
client = kfp.Client(proxy=f"http://{kfp_proxy_host}:{kfp_proxy_port}") #client = kfp.Client()
experiment = client.get_experiment(experiment_name=experiment_name) list_runs = client.list_runs(experiment_id=experiment.id, page_size=0) runs = list_runs.runs
best_model = {'path': 'None', 'acc': goal_acc} for run in runs:
run_dict = run.to_dict() if run_dict['storage_state'] == 'STORAGESTATE_ARCHIVED': continue if run_dict['metrics'] is None: continue if run_dict['status'] != 'Succeeded': continue if run_dict['pipeline_spec']['parameters'] is None: continue model = {'version': run_dict['metrics'][0]['number_value'], 'acc': run_dict['metrics'][1]['number_value']} if best_model['acc'] < model['acc']: best_model = model print(best_model)
from collections import namedtuple result = namedtuple('BestModel', ['version', 'acc'])
return result(best_model['version'], best_model['acc'])
def get_last_dataset(dataset_path: str) -> str: import fnmatch import numpy as np import os files = fnmatch.filter(os.listdir(dataset_path), '*.npz') files.sort(key=lambda fn: os.path.getmtime(os.path.join(dataset_path, fn))) last_dataset = os.path.join(dataset_path, files[1]) print(last_dataset) return last_dataset
from typing import NamedTuple
def train_from_best_model(model_version: float, new_dataset_path: str) \ -> NamedTuple('Outputs', [('mlpipeline_metrics', 'Metrics'), ('model_version', str)]): import datetime import time import json import os import shutil from kubeflow import katib from kubeflow.katib import KatibClient
from kubernetes.client import V1ObjectMeta from kubeflow.katib import V1beta1Experiment from kubeflow.katib import V1beta1AlgorithmSpec from kubeflow.katib import V1beta1ObjectiveSpec from kubeflow.katib import V1beta1FeasibleSpace from kubeflow.katib import V1beta1ExperimentSpec from kubeflow.katib import V1beta1ObjectiveSpec from kubeflow.katib import V1beta1ParameterSpec from kubeflow.katib import V1beta1TrialTemplate from kubeflow.katib import V1beta1TrialParameterSpec
def find_metrics(_list, name, _type): return next(filter(lambda _list: _list['name'] == name, _list))[_type] def move_dataset(orig_path): target_dir = "/notebook/new_dataset/retrain" os.makedirs(target_dir, exist_ok=True) npz = os.path.basename(orig_path) shutil.copy(orig_path, f'{target_dir}/{npz}')
kclient = KatibClient() kclient.list_experiments() date_postfix = datetime.datetime.now().strftime("%Y%m%d%H%M%S") experiment_name = f"my-model-retrain-{date_postfix}" objective_metric_name = "Validation-accuracy"
metadata = V1ObjectMeta( name=experiment_name )
algorithm_spec = V1beta1AlgorithmSpec( algorithm_name="random" )
objective_spec = V1beta1ObjectiveSpec( type="maximize", goal=0.99, objective_metric_name=objective_metric_name, additional_metric_names=["Validation-loss", "accuracy", "loss"] )
parameters = [ V1beta1ParameterSpec( name="epoch", parameter_type="int", feasible_space=V1beta1FeasibleSpace( min="10", max="30" ), ), ]
# JSON template specification for the Trial's Worker Kubernetes Job. trial_spec = { "apiVersion": "batch/v1", "kind": "Job", "spec": { "template": { "metadata": { "annotations": { "sidecar.istio.io/inject": "false" } }, "spec": { "containers": [ { "name": "training-container", "image": "yourID/fashion-mnist-retrain:handson.rc4", "volumeMounts": [ {"name": "notebook", "mountPath": "/notebook"}, ], "command": [ "python", "/app/my_model_retrain.py", "--node_amount=${trialParameters.epoch}", f"--dataset_path={new_dataset_path}", f"--model_path=/notebook/model/{model_version}",
] } ], "restartPolicy": "Never", "volumes": [ {"name": "notebook", "persistentVolumeClaim": {"claimName": "workspace-handson"} } ] } } } }
# Configure parameters for the Trial template. trial_template = V1beta1TrialTemplate( primary_container_name="training-container", trial_parameters=[ V1beta1TrialParameterSpec( name="epoch", description="train epoch", reference="epoch" ), ], trial_spec=trial_spec )
# Experiment object. experiment = V1beta1Experiment( api_version="kubeflow.org/v1beta1", kind="Experiment", metadata=metadata, spec=V1beta1ExperimentSpec( max_trial_count=3, parallel_trial_count=30, max_failed_trial_count=3, algorithm=algorithm_spec, objective=objective_spec, parameters=parameters, resume_policy=None, trial_template=trial_template, ) ) kclient.create_experiment(experiment) accuracy = 0.0 while 1: time.sleep(60) status = kclient.get_experiment_status(experiment_name) result = kclient.get_optimal_hyperparameters(experiment_name) if status == "Running": print(f"{experiment_name} is running") if status == "Succeeded": if result: metrics = result['currentOptimalTrial']['observation']['metrics'] val_acc = find_metrics(metrics, objective_metric_name, 'max') move_dataset(new_dataset_path) break
metrics = { 'metrics': [{ 'name': 'val-acc', 'numberValue': float(val_acc), 'format': "PERCENTAGE", }] } from collections import namedtuple result = namedtuple('Outputs', ['mlpipeline_metrics', 'model_version']) return result(json.dumps(metrics), model_version)
def disable_cache(op): op.execution_options.caching_strategy.max_cache_staleness = "P0D"
def container_op(func): return func_to_container_op(func, base_image="dudaji/cap-jupyterlab:tf2.0-cpu")
def train_pipeline(goal_acc: float = 0.40, dataset_path: str = "/notebook/new_dataset/train"): notebook_vol = dsl.PipelineVolume(pvc="workspace-handson")
model_op = container_op(get_best_model) dataset_op = container_op(get_last_dataset) train_op = container_op(train_from_best_model)
model_comp = model_op(goal_acc) \ .add_pvolumes(pvolumes={"/notebook": notebook_vol})
dataset_comp = dataset_op(dataset_path) \ .add_pvolumes(pvolumes={"/notebook": notebook_vol})
train_comp = train_op(model_version=model_comp.outputs['version'], new_dataset_path=dataset_comp.output) \ .add_pvolumes(pvolumes={"/notebook": notebook_vol}) disable_cache(dataset_comp) disable_cache(model_comp) disable_cache(train_comp)
arguments = {"goal_acc": 0.40, "dataset_path": "/notebook/new_dataset/train"}
client = kfp.Client()client.create_run_from_pipeline_func(train_pipeline, experiment_name="train_model", arguments=arguments)
kfp.compiler.Compiler().compile(pipeline_func=train_pipeline, package_path='train_pipeline.yaml')
client.upload_pipeline(pipeline_name="train_pipeline", description="Train from best model", pipeline_package_path="train_pipeline.yaml") 모델 업데이트 파이프라인 - 컴포넌트 재활용#
마지막으로 운영중인 모델보다 재학습을 통해 얻어진 모델이 더 좋은 정확도를 가진다면 현재의 모델을 교체하는 파이프라인을 만들어 보겠습니다.
작업중
‼️ 모델 업데이트 파이프라인은 아직 작성중입니다.