Pipeline 만들기
시작하면서#
이번 과정도 개발을 위한 준비 챕터에서 만든 handson 노트북서버에서 진행됩니다.
info
사용되는 코드는 아래 링크에서 보실 수 있습니다.
10.pipeline_tutorial.ipynb
11.simple_pipeline.ipynb
12.pipeline_compile.ipynb
13.conditional_pipeline.ipynb
Goal#
- 파이프라인 이해하기
- 다양한 방법으로 파이프라인 생성하기
머신러닝 워크플로우#
note
머신러닝 워크플로우는 일반적으로 "데이터의 주기적 공급 -> 모델의 재학습 -> 모델의 최신화" 와 같은 단계로 이루어집니다. 이번 장 부터 마지막 장까지 과정에서 fashion mnist 데이터를 주기적으로 생성하고 그 데이터를 기반으로 모델을 학습시킨 후, 그 모델이 기존 서비스되고 있는 모델보다 성능이 좋다면 교체하는 워크플로우를 파이프라인으로 구성해보겠습니다.
파이프라인 이해하기#
파이프라인의 개념#
CAP의 파이프라인은 아래와 같이 구성됩니다.
- 파이프라인 실행을 관리/추적하는 사용자 인터페이스
- 여러 단계의 워크플로우를 스케쥴링 하는 엔진
- 파이프라인과 그 컴포넌트를 만드는 SDK
- SDK를 사용하는 시스템과의 상호연동을 위한 노트북 서버
여기서 파이프라인은 워크플로우의 컴포넌트들이 그래프 형태로 결합되어 있는 것을 뜻합니다.
파이프라인 (Pipelines)#
파이프라인 그래프
- 컴포넌트 : 입력과 출력을 가진 하나의 독립적인 일을 처리하는 컨테이너입니다. 하나의 함수로 봐도 무방합니다. 하나의 컴포넌트는 하나의 독립적인 프로세스로 실행되며 다른 컴포넌트에 값을 전달 하기 위해서는 문자열이나 파일로 직렬화(serialization)하여 보내야 합니다.
- 그래프 : 파이프라인 컴포넌트가 실행되었거나 실행 중인 단계를 보여주며, 그래프가 나타내는 화살표는 각 단계가 나타내는 파이프라인 컴포넌트 간의 상위/하위 실행 관계를 나타냅니다.
런(RUNS) & 익스페리먼트(Experiments)#
파이프라인은 런(Run)이라는 실행단위를 가집니다. 즉 파이프라인을 실행하면 하나의 런이 생성됩니다. 실행된 런은 Experiments라고 불리는 워크스페이스에 속해집니다. Run의 논리적 그룹이라고 할 수 있습니다.
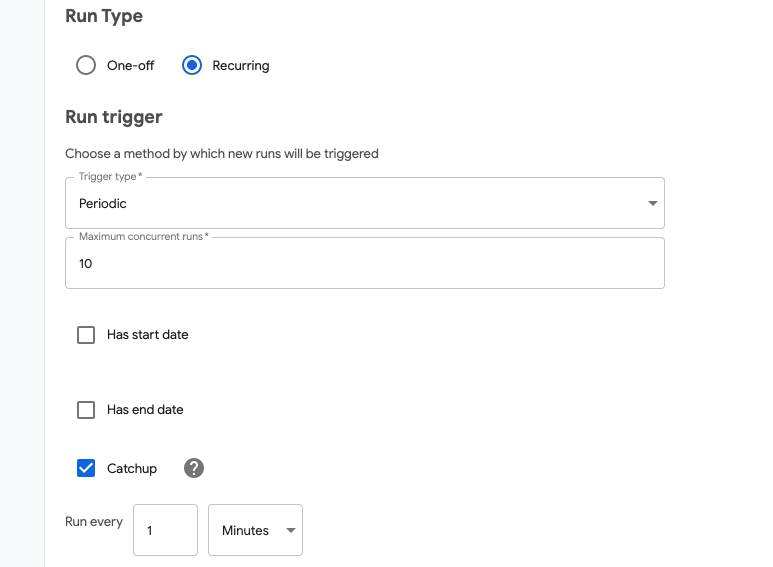
리커링 런 (Recurring Runs)#
런이 일회성 실행이라면 주기적인 실행, CronJob 같은 리커링(Recurring)런도 존재합니다.
각종 옵션들을 이용해 주기적인 실행이 필요한 런에 효과적으로 사용할 수 있습니다.
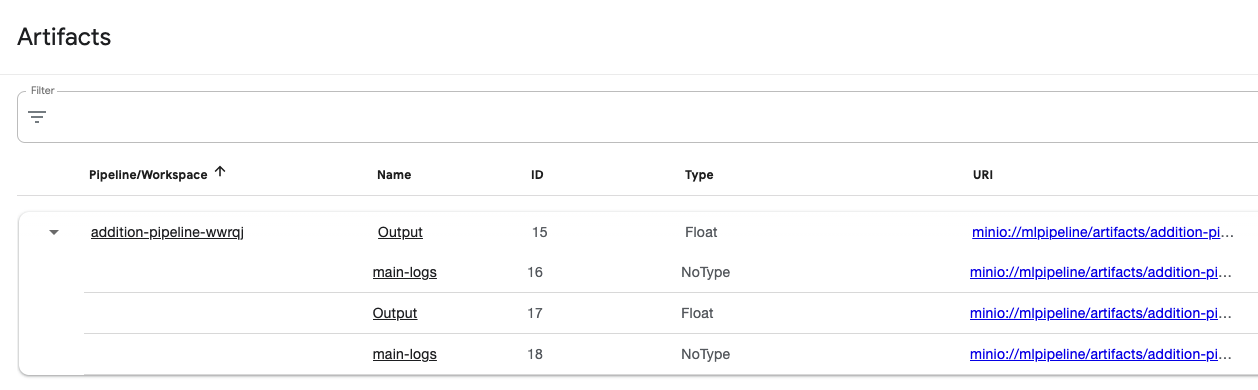
아티팩트(Artifacts)#
Artifacts 는 파이프라인 컴포넌트들의 입출력과 로그 등을 자동으로 스토리지에 저장합니다.
그 결과를 시각적인 UI로 제공해주기 때문에 결과에 따른 결정이나 판단을 쉽게 할 수 있게 도와줍니다.
파이프라인 SDK#
파이프라인은 SDK를 이용해 생성할 수 있습니다. 파이프라인 SDK는 python 패키지로 제공됩니다.
SDK는 크게 4가지의 패키지로 구성됩니다.
kfp.compiler
python 으로 작성된 파이프라인 코드를 등록할 수 있게 클러스터 리소스(YAML) 형태로 컴파일러를 제공하는 패키지입니다.kfp.components
컴포넌트간의 상호작용을 위한 클래스와 함수를 제공하는 패키지입니다.kfp.dsl
컴포넌트를 정의하는데 필요한 패키지로 컴포넌트를 만들기 위한 데코레이터 등이 포함되어 있습니다.kfp.Client
파이프라인 API 서버와 통신하기 위한 python 클라이언트 패키지입니다. CAP은 노트북에서 사용합니다. 파이프라인을 실행하거나 생성하는 역할을 합니다.
아래는 SDK를 통해서 add 라는 python 함수를 파이프라인의 런으로 실행시키는 코드입니다.
pipeline_tutorial라는 이름의 노트북을 만들어서 아래 코드를 실행합시다.
# pipeline_tutorial.ipynbimport kfpimport kfp.dsl as dslfrom kfp.components import create_component_from_func
# ①client = kfp.Client()
# ②def add(a: float, b: float) -> float: '''Calculates sum of two arguments''' return a + b
add_op = create_component_from_func(add)
# ③@dsl.pipeline( name='Add pipeline', description='An example pipeline that performs addition calculations.')def add_pipeline( a='1', b='7',): add_op(a, b)
# ④arguments = {'a': '7', 'b': '8'}client.create_run_from_pipeline_func(add_pipeline, arguments=arguments)
크게 4가지 영역으로 나눌 수 있습니다.
① 파이프라인 서버 연결을 위한 클라이언트 생성
② 컴포넌트 생성 코드
create_component_from_func 를 이용하여 python 함수를 파이프라인 컴포넌트화 합니다.
@create_component_from_func 데코레이터를 사용해서 아래와 같이 정의할 수 있습니다.
@create_component_from_funcdef add_op(a: float, b: float) -> float: '''Calculates sum of two arguments'''return a + b③ 파이프라인 생성 코드
@dsl.pipeline 라는 데코레이터를 이용해서 add_op를 포함하는 파이프라인을 작성하는 함수
④ 파이프라인 실행
create_run_from_pipeline_func 를 이용해서 파이프라인 런(RUN)을 생성 후 실행합니다.
다시 정리하면 파이프라인 SDK를 이용한 파이프라인 생성 순서는
프로세스(함수) 구현 → 컴포넌트 생성 → 파이프라인 생성 → 실행
의 구성으로 이루어집니다.
tip
파이프라인의 개념에서 컴포넌트는 컨테이너라고 설명을 드렸습니다. 하지만 add_pipeline 함수에서는 컨테이너에 대한 정의가 없습니다. 파이프라인 SDK는 별도의 베이스 이미지를 선택하지 않으면 기본적으로 python 3.7 컨테이너 이미지로 컨테이너화를 진행합니다.
이제 간단한 예제를 따라하며 파이프라인 SDK를 익혀보겠습니다.
컴포넌트간의 데이터 전달#
아까 만들었던 add_op 의 결과값을 받아서 제곱 값을 반환하는 컴포넌트를 만들고 파이프라인을 구성해보겠습니다. 먼저 add_op와 power_op 함수를 작성해보겠습니다. 둘 다 데코레이터를 사용해 정의합니다.
simple_pipeline.ipynb 라는 빈 노트북을 생성합니다.
# simple_pipeline.ipynbimport kfpimport kfp.dsl as dslfrom kfp.components import create_component_from_func
client = kfp.Client()
@create_component_from_funcdef add_op(a: float, b: float) -> float: return a + b
@create_component_from_funcdef power_op(a: float) -> float: return a * a
그리고 파이프라인을 정의해 보곘습니다.
@dsl.pipeline( name='Add-power pipeline')def add_power_pipeline(a: float = 1, b: float = 1): first_task = add_op(a, b) second_task = power_op(first_task.output)
arguments = {'a': '7', 'b': '8'}client.create_run_from_pipeline_func(add_power_pipeline, arguments=arguments)
여기서 first_task=add_op(a,b) 의 결과값을 output 을 이용해 접근한다는 것을 알 수 있습니다.
단일 반환값일 경우 별도로 아웃풋 설정을 하지 않았을때 output 으로 접근 가능하며,
2개 이상의 값이거나 따로 설정을 했다면 outputs['output_name'] 형태로 접근 가능합니다.

파이프라인 UI로 이동하여 정상적으로 생성되었는지 확인해 보겠습니다.
링크오류
현재 1.3 버전에서 Experiment details 나 Run details 링크로 파이프라인 UI로 이동이 불가능합니다.
파이프라인이 미생성 된 것은 아니니 대시보드를 이용해 이동해주세요
홈 대시보드에서 Pipeline ➔ Experiments로 이동합니다.
실행시 별도의 Experiments를 정의하지 않았기 때문에 Default에서 실행됩니다.
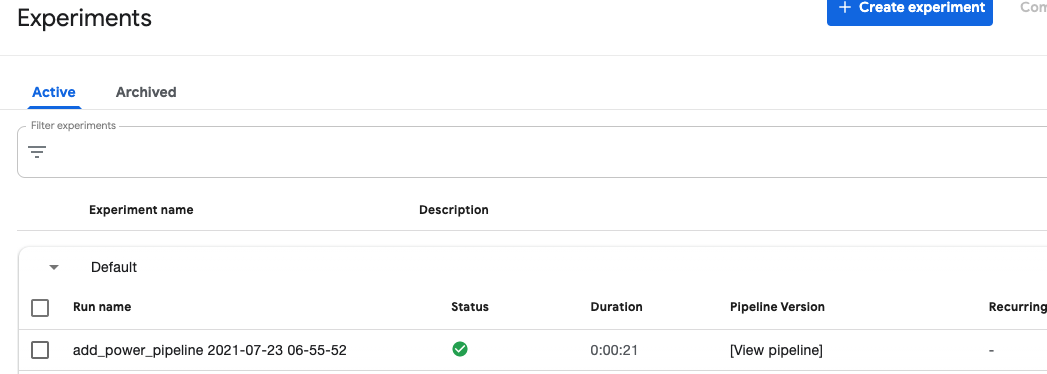
노트북에서 오류가 나지 않았다면, 정상적으로 실행이 된 것을 확인할 수 있습니다.
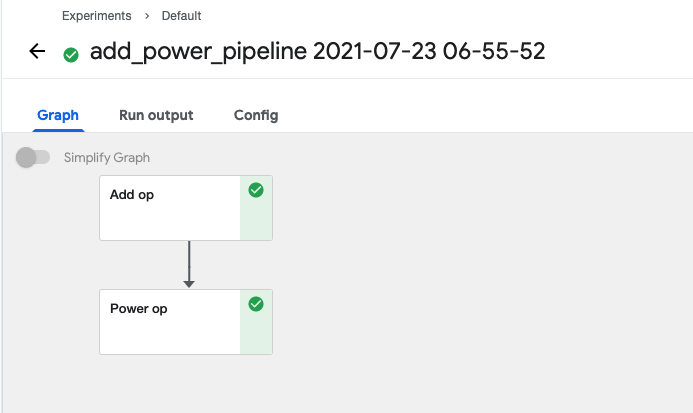
런(Run) 이름을 클릭하면 실제로 실행된 컴포넌트의 그래프를 볼 수 있습니다.
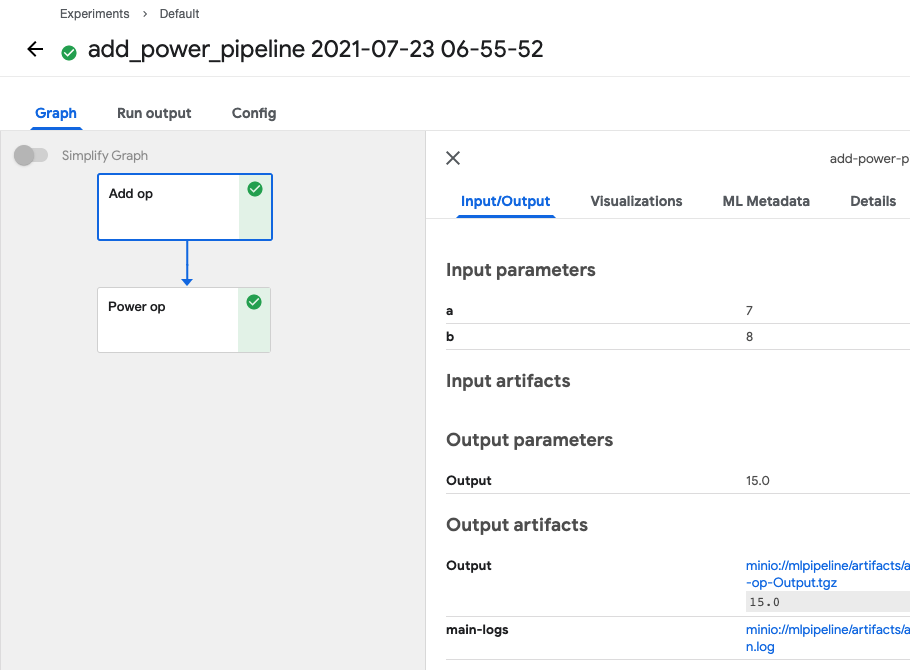
각각의 컴포넌트를 클릭해보면 Input 과 Output에 대한 정보를 확인할 수 있습니다.
또한 Output artifacts 에서 결과와 로그들을 다운로드 받을 수 있습니다.
모든 컴포넌트들의 output은 파일로 반환되어 오브젝트 스토리지에 담겨 링크 형태로 제공됩니다.
(minio://mlpipeline/... )
이제 하나의 결과 값이 아닌 여러 개의 값을 전달하는 컴포넌트를 만들어 보겠습니다.
두 수가 들어오면 그 수의 합과 곱을 전달하는 함수를 만들겠습니다.
함수 선언시 Return 타입 힌트를 typing.NamedTuple로 정의하고 실제 반환시 collections.namedtuple를 사용합니다.
그리고 함수에 @create_component_from_func 데코레이터를 붙여 컴포넌트로 완성합시다.
# simple_pipeline.ipynbfrom typing import NamedTuplefrom collections import namedtuplefrom kfp.components import create_component_from_func
@create_component_from_funcdef sum_product_op(a: float, b: float) -> NamedTuple('TwoOutputs', [('sum', float), ('product', float)]): sum_result = a + b product_result = a * b
two_output = namedtuple('TwoOutputs', ['sum', 'product']) return two_output(sum_result, product_result)컴포넌트가 완성되었다면, 파이프라인 함수로 만들어 봅시다.
# simple_pipeline.ipynbdef sum_product_pipeline(a: float = 1, b: float = 1): sum_product_op(a, b)파이프라인 컴파일을 사용하여 파이프라인 등록하기#
이전 단계에서 함수를 컴포넌트로 만들고 파이프라인 함수화하여 바로 RUN으로 실행시켰습니다. 일회성 실행(Job)이라면 상관없지만 RUN으로만 존재하는 컴포넌트는 관리가 힘듭니다. 파이프라인의 컴파일 함수는 python 코드로 만든 함수를 YAML 템플릿 형태로 변환하여 재사용과 관리를 용이하게 해줍니다.
이전 단계에서 만든 sum_product_pipeline을 컴파일한 후 파이프라인 UI에 등록해봅시다.
# pipeline_compile.ipynbkfp.compiler.Compiler().compile( pipeline_func=sum_product_pipeline, package_path='sum_product_pipeline.yaml')컴파일 과정은 간단합니다. 실행하면 sum_product_pipeline.yaml 파일이 생성되어 저장됩니다.
컴파일을 하는 전체 코드는 아래와 같습니다.
# pipeline_compile.ipynb import kfpfrom typing import NamedTuplefrom collections import namedtuplefrom kfp.components import create_component_from_func
@create_component_from_funcdef sum_product_op(a: float, b: float) -> NamedTuple('TwoOutputs', [('sum', float), ('product', float)]): sum_result = a + b product_result = a * b
two_output = namedtuple('TwoOutputs', ['sum', 'product']) return two_output(sum_result, product_result)
def sum_product_pipeline(a: float = 1, b: float = 1): sum_product_op(a, b)
kfp.compiler.Compiler().compile( pipeline_func=sum_product_pipeline, package_path='sum_product_pipeline.yaml')저장된 sum_product_pipeline.yaml 을 열어보면
apiVersion: argoproj.io/v1alpha1kind: Workflowmetadata: generateName: sum-product-pipeline- annotations: {pipelines.kubeflow.org/kfp_sdk_version: 1.6.6, pipelines.kubeflow.org/pipeline_compilation_time: '2021-08-11T04:13:03.419092', pipelines.kubeflow.org/pipeline_spec: '{"inputs": [{"default": "1", "name": "a", "optional": true, "type": "Float"}, {"default": "1", "name": "b", "optional": true, "type": "Float"}], "name": "Sum product pipeline"}'} labels: {pipelines.kubeflow.org/kfp_sdk_version: 1.6.6}spec: entrypoint: sum-product-pipeline templates: - name: sum-product-op container: args: [--a, '{{inputs.parameters.a}}', --b, '{{inputs.parameters.b}}', '----output-paths', /tmp/outputs/sum/data, /tmp/outputs/product/data] command: - sh - -ec - | program_path=$(mktemp) printf "%s" "$0" > "$program_path" python3 -u "$program_path" "$@" - | def sum_product_op(a, b): sum_result = a + b product_result = a * b
two_output = namedtuple('TwoOutputs', ['sum', 'product']) return two_output(sum_result, product_result)
def _serialize_float(float_value: float) -> str: if isinstance(float_value, str): return float_value if not isinstance(float_value, (float, int)): raise TypeError('Value "{}" has type "{}" instead of float.'.format(str(float_value), str(type(float_value)))) return str(float_value)... (중략)위의 코드가 yaml로 변환된 것을 확인할 수 있습니다. 이 파일을 업로드 하기 위해 일단 다운로드 받습니다.
tip
주피터랩에서 파일을 다운로드 받으려면 원하는 파일을 마우스 우클릭하여 나오는 탭에서 Download를 클릭하면 됩니다.
이제 파이프라인 UI로 이동해 등록을 진행합니다.
Pipelines 메뉴에서 Upload pipeline 이란 버튼을 클릭하면 등록 화면으로 이동합니다.
Upload a file 탭에서 sum_product_pipeline.yaml을 업로드 한 후 이름과 설명을 적은 후 Create 버튼을 누릅니다.
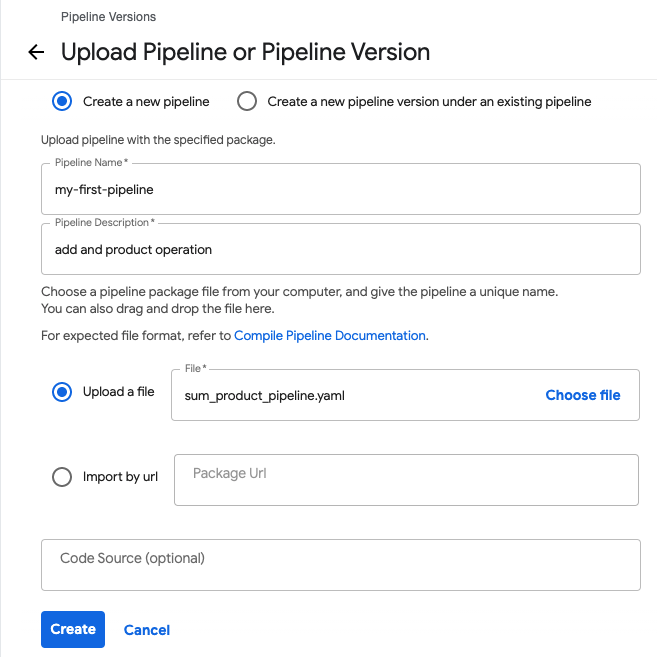

파이프라인이 등록되었습니다. Create run을 통해 RUN을 실행해 봅시다!
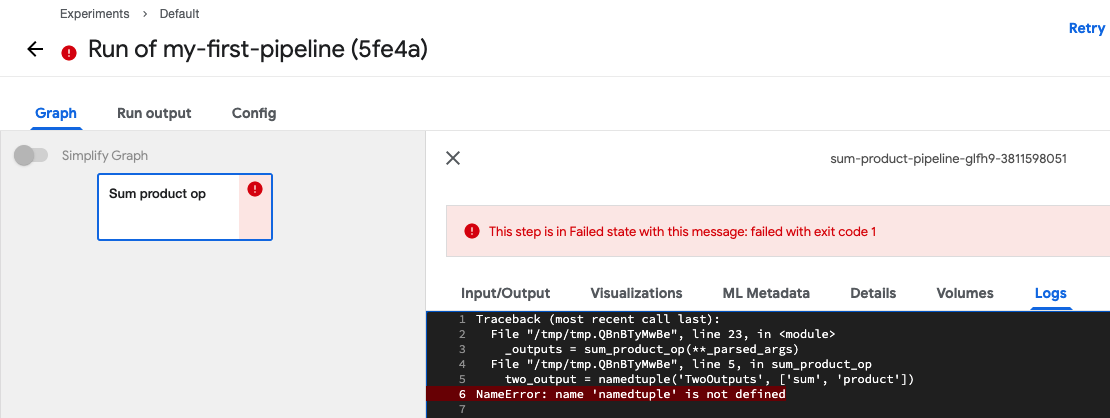
⚠️ 오류가 발생하였습니다. namedtuple이 없다는 메시지입니다.
중요
함수를 파이프라인 컴포넌트로 변환할 때 주의할 사항이 있습니다.
컴포넌트로 변환될 함수 내부의 어떤 코드도 함수 밖에서 선언하면 안됩니다.
namedtuple이 함수 외부에서 import 되어 있기 때문에 함수 안으로 import 구문을 옮겨줍니다.
# pipeline_compile.ipynb ... product_result = a * b from collections import namedtuple two_output = namedtuple('TwoOutputs', ['sum', 'product']) ...이번엔 수정된 파이프라인 코드를 UI가 아닌 SDK로 올려보겠습니다.
파이프라인 SDK는 아래와 같은 함수를 제공합니다.
upload_pipeline( pipeline_package_path: str = None, pipeline_name: str = None, description: str = None)
upload_pipeline_version( pipeline_package_path, pipeline_version_name: str, pipeline_id: Optional[str] = None, pipeline_name: Optional[str] = None)이미 업로드된 파이프라인은 namedtuple 관련 오류가 발생하여 삭제를 하고 다시 올려야 하지만 upload_pipeline_version를 이용해 버전을 달리하여 올려보도록 하겠습니다.
tip
파이프라인의 버전 이름은 unique 해야 합니다.
새로운 셀을 만들어 아래 코드를 추가하고 실행합니다.
# pipeline_compile.ipynb
client = kfp.Client() client.upload_pipeline_version(pipeline_name="my-first-pipeline", pipeline_package_path="sum_product_pipeline.yaml", pipeline_version_name="bugfix") 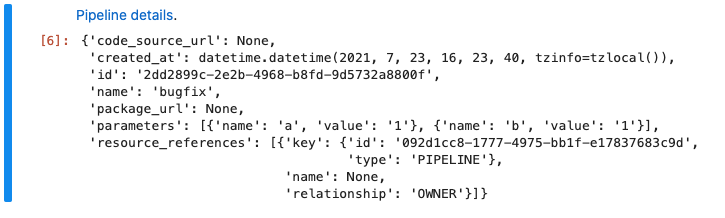
업로드가 완료되면 파이프라인UI로 가서 확인해봅니다.
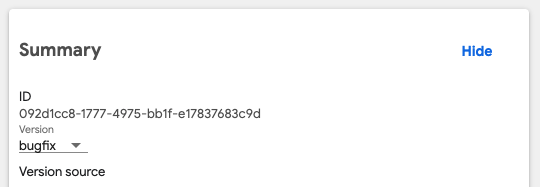
bugfix 버전이 적용된 것을 알 수 있습니다. 이제 다시 RUN을 생성해보겠습니다.
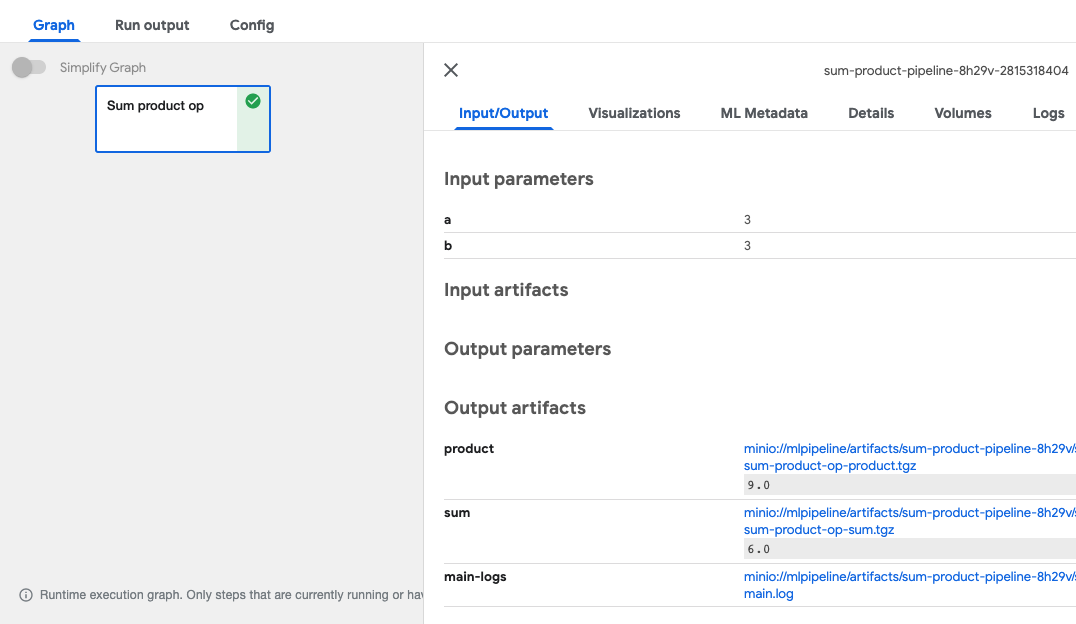
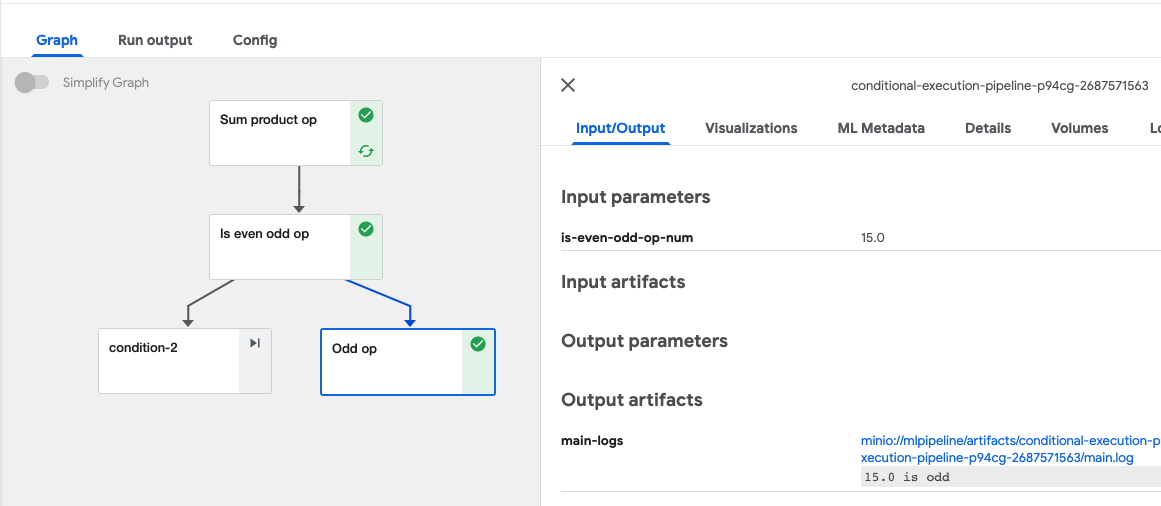
Output artifacts에서 product와 sum의 값을 확인할 수 있습니다.
조건에 따라 컴포넌트 실행해보기#
컴포넌트의 결과 값에 따라서 분기를 지정해 실행하는 것도 가능합니다.
이전 단계의 파이프라인 컴포넌트에서 sum을 실행한 값이 짝수면 even이라는 컴포넌트로,
홀수면 odd라는 컴포넌트로 실행하는 파이프라인을 만들어 보겠습니다.
주의
함수를 컴포넌트화 할때 함수 안에 한글 주석이 있으면 에러가 발생합니다. 주석이 꼭 필요하다면 영어로 작성해주세요
# conditional_pipleine.ipynb @create_component_from_funcdef is_even_odd_op(num: float) -> NamedTuple('TwoOutputs', [('num', float), ('num_type', str)]): num_type = "even" if round(num) % 2 == 1: num_type = "odd" from collections import namedtuple
two_outputs = namedtuple('TwoOutputs', ['num', 'num_type']) return two_outputs(num, num_type)
@create_component_from_funcdef odd_op(num: float): print(f"{num} is odd")
@create_component_from_funcdef even_op(num: float): print(f"{num} is even")
총 3개의 컴포넌트가 만들어 졌습니다.
이제 파이프라인으로 만들어 봅시다.
note
결과값에 따라 분기를 설정하는 것은 dsl 패키지의 Condition를 사용합니다.
kfp.dsl.Condition(condition, name=None)
Parameters: - condition (ConditionOperator) – the condition. - name (str) – name of the condition# conditional_pipleine.ipynb from kfp import dsl
@dsl.pipeline( name='Conditional execution pipeline')def is_odd_even_pipeline(a: float = 1, b: float = 1): sum_result = sum_product_op(a, b) is_even_odd_result = is_even_odd_op(sum_result.outputs['sum']) num_type = is_even_odd_result.outputs['num_type'] num = is_even_odd_result.outputs['num'] with dsl.Condition(num_type == 'odd'): odd_op(num) with dsl.Condition(num_type == 'even'): even_op(num) arguments = {'a': '7', 'b': '8'}client.create_run_from_pipeline_func(is_odd_even_pipeline, arguments=arguments)
tip
여기서 is_even_odd_op 라는 함수를 만들어 사용하는 이유가 궁금하실 수 있습니다.
with dsl.Condition(sum_result.outputs['sum'] % 2 == 1): odd_op(num)위와 같이 단순한 계산식을 쓰면 좋겠지만 , 파이프라인의 결과값은 PipelineParam이라는 오브젝트 로 반환됩니다. 이 오브젝트는 비교연산을 제외하고는 다른 연산을 지원하지 않습니다.
즉, PipelineParam와 다른 데이터 타입(숫자형 같은)과 연산을 할 수 없습니다. 그렇기 때문에 다른 컴포넌트의 매개변수로 입력되어 연산을 진행해야 합니다.
조건문 코드가 완성되었다면 실행시킨 후 파이프라인 UI에서 확인해보도록 하겠습니다.