Fashion mnist 로 모델 개발하기
시작하면서#
Fashion mnist 데이터셋을 가지고 NN(Neural Network) 모델을 만들어 보겠습니다.
Fashion mnist 데이터셋은 mnist와 마찬가지로 10개의 의류 클래스(티셔츠, 트라우저..)를 가지고 있습니다.
각 이미지는 28x28 크기이며 60,000장의 train dataset과 10,000장의 test dataset을 가지고 있습니다.
상세한 정보는 https://github.com/zalandoresearch/fashion-mnist에서 확인이 가능합니다.
그리고 CAP에서 제공하는 Tensorboard 툴을 이용하여 모델의 학습로그를 확인해 보겠습니다.
info
이번 장의 모든 과정은 개발을 위한 준비에서 만든 handson 노트북서버에서 진행됩니다.
사용되는 코드는 아래 링크에서 보실 수 있습니다.
01.fashion_mnist_model.ipynb에서 전체 코드를 확인하시 수 있습니다.
Goal#
- Fashion mnist 데이터셋으로 NN 모델 개발/ 학습해보기
- 모델의 학습 로그를 Tensorboard로 보기
Fashion mnist 데이터셋으로 NN모델 개발&학습시키기#
데이터셋 확인하기#
- 노트북 서버에 접속한 후 처음 만나는 화면은 노트북을 생성하는 Launcher 입니다.
여기서 Python 3 버튼을 클릭하면 python3 runtime을 가지는 노트북이 생성이 됩니다.
초기화면

fashion_mnist_model.ipynb 이라는 이름의 Python3 노트북을 만들어 봅시다.
➕ 버튼을 눌러 노트북을 생성하면 Untitled.ipynb라는 노트북이 생성됩니다.
좌측 사이드탭의 파일명에 마우스 우클릭을 하면 아래와 같이 상세 메뉴가 뜹니다.
Rename을 선택하여 이름을 변경하시면 됩니다.
파일 이름 변경
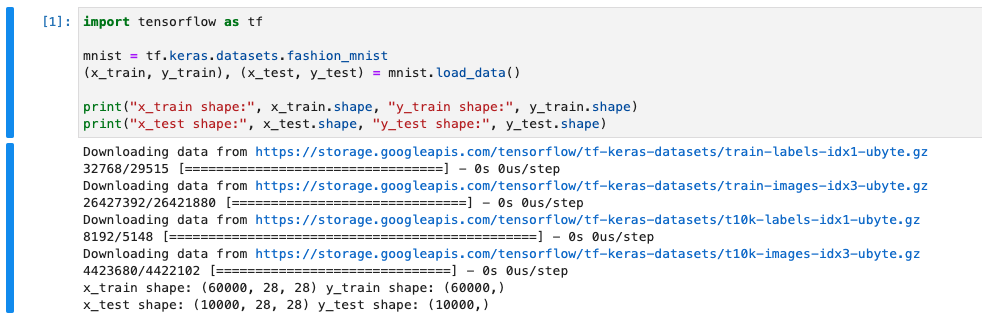
이제 첫번째 셀을 클릭하여 tf.keras.datasets 에서 fashion mnist 데이터셋을 가져오는 코드를 작성합니다.
아래의 코드를 작성하고 실행하면, 사이즈의 트레인 데이터셋 60,000개와 테스트 데이터셋 10,000개가 존재하는 것을 확인 할 수 있습니다. 처음 fashion_mnist 데이터 셋을 호출하면 $HOME/.keras/dataset 경로에 다운로드를 진행하고 그 다음 실행부터는 로컬에 저장된 데이터셋을 이용합니다.
# fashion_mnist_model.ipynb import tensorflow as tf
mnist = tf.keras.datasets.fashion_mnist(x_train, y_train), (x_test, y_test) = mnist.load_data()
print("x_train shape:", x_train.shape, "y_train shape:", y_train.shape)print("x_test shape:", x_test.shape, "y_test shape:", y_test.shape)
데이터셋 로드
Jupyter Notebook의 장점 중 하나는 바로 시각화가 편한 것입니다. matplotlib 라이브러리의
show()를 사용해 트레인 데이터셋의 이미지를 시각화하여 데이터셋의 이미지 중 하나를 살펴 보겠습니다.
먼저 matplotlib을 설치 한 후 진행합니다.
!python -m pip install -U pip!python -m pip install -U matplotlibtip
노트북 셀에서 !를 제일 앞에 넣어주면 terminal 커맨드를 사용할 수 있습니다.
- 설치가 완료되면 fashion_mnist_model.ipynb 에 아래 코드를 작성하여 실행시켜봅시다.
# fashion_mnist_model.ipynb
import matplotlib.pyplot as pltimport random# 10개의 클래스 이름은 아래와 같습니다.class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
img_index = random.randrange(0, 59999)label_index = y_train[img_index]print (f"img_index = {img_index}, y = {label_index} {class_names[label_index]}")plt.imshow(x_train[img_index])plt.colorbar()plt.show() 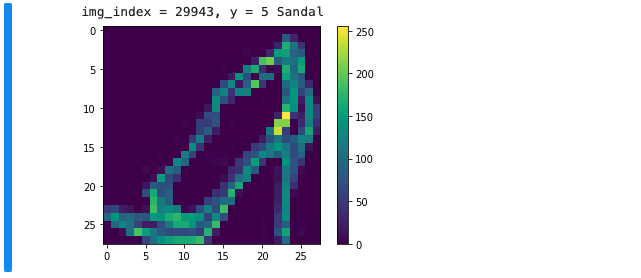
데이터셋 정규화하기 (Normalization)#
이렇게 사람은 이미지를 시각화하여 확인할 수 있지만, 머신러닝 모델에서의 학습은 0에서 255까지의 픽셀값을 가진
의 Numpy 배열이 사용됩니다.
따라서 정규화 과정을 거쳐 각각의 이미지들의 픽셀값을 [0-255] 에서 [0-1]범위로 줄여줄 것입니다.
정규화 과정은 왜 필요할까요?
사진 한장이 가지고 있는 특성이(픽셀값이) 0~255 사이의 값을 가지게 되면, 그 한 장이 학습에 영향을 미치는 비중도 이 특성값의 크기에 영향을 받게 됩니다. 이를 모두 255로 나누어 0~1사이의 값으로 낮춰줌으로써, 사진 하나하나가 학습에 영향을 미치는 비중을 동등하게 만들어 줄 수 있습니다. 이는 곧 학습의 속도와 정확성을 높일 수 있게 됩니다.
# fashion_mnist_model.ipynbx_train, x_test = x_train / 255.0, x_test / 255.0 # 정규화모델 구성하기#
Fashion mnist 데이터셋으로 인공신경망(Neural Network) 모델을 구성할 것입니다.
keras의 Sequential를 이용하여 아래와 같이 구성합니다. 이 모델은 총 4개의 레이어로 구성됩니다.
# fashion_mnist_model.ipynb
model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax')])- 첫번째 레이어는 2차원 배열( 픽셀)의 이미지 포맷을 픽셀의 1차원 배열로 변환합니다.
이 레이어는 이미지에 있는 픽셀의 행을 펼쳐서 일렬로 늘리는 역할 Flatten 을 합니다. - 그리고 128개의 노드를 가진 Fully connected (Dense) 레이어를 추가합니다.
- 과적합(overfitting)방지를 위한 Dropout 레이어를 추가합니다. 여기서는 20%의 노드를 무작위로 0으로 만듭니다.
- 마지막으로 10개 노드와 소프트맥스를 활성함수로 가진 Fully connected (Dense) 레이어를 추가합니다.
이 레이어는 전체의 합이 1이 되는 10개의 확률값을 반환합니다.
즉, 각 노드는 현재 이미지가 10개의 클래스 중 하나일 확률값을 출력하게 됩니다.
모델 컴파일하기#
위에서 4개의 레이어로 구성된 인공신경망을 구성했습니다. 이제 이 모델을 학습시키기 위해 컴파일(model.compile)이라는 과정을 거쳐야 합니다. 컴파일을 위해선 아래와 같이 몇가지를 추가해주어야 합니다.
- 옵티마이저(Optimizer): 데이터와 손실함수를 바탕으로 모델의 업데이트 방향을 결정합니다.
- 손실함수(Loss function): 훈련하는 동안의 모델의 오차를 측정합니다.
모델이 올바른 방향으로 학습하도록 이 함수를 최소화 해야합니다. - 지표(Metrics): 훈련과 테스트 단계를 모니터링하기 위한 항목을 설정합니다.
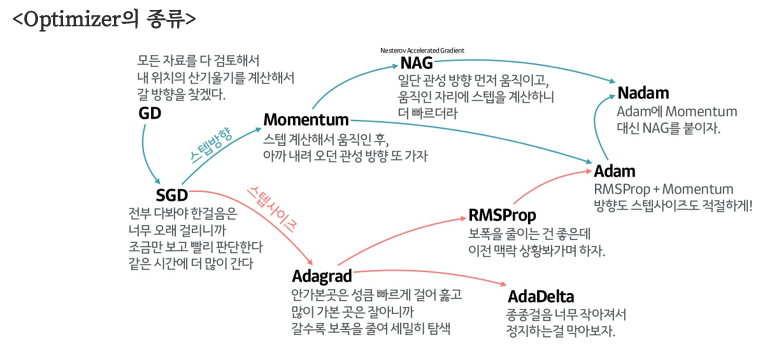
# fashion_mnist_model.ipynbmodel.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics=['acc'])- 이 모델은 옵티마이저로 확률적 경사 하강법(Stochastic Gradient Descent, SGD)을 사용합니다.
SGD
SGD는 mini-batch 사이즈만큼 일부 데이터의 모음을 가지고 조금씩 훈련을 시켜서 최적의 값을 찾는 방법입니다. 이 방법은 정확도가 낮아 질 수 있지만, 계산 속도가 빨라 학습 시간을 줄일 수 있으며, Local Minima 문제에 빠지지 않고 더 좋은 방향으로 수렴할 가능성을 높여줍니다.
- 손실함수(Loss Function)는 멀티클래스 분류에 사용되는 categorical cross-entropy를 사용합니다.
Categorical CrossEntropy
sparse_categorical_crossentropy 는 라벨링된 클래스 분류가 정수일때 사용합니다.
ex) y_train(test) 가 [0,1,2,3,4,5,6,7,8,9] 형태
categorical_crossentropy는 는 0이나 1로 라벨링된 클래스 분류 데이터에 사용합니다.
ex) y_train(test) 가 [1,0,0,0,0,0,0,0,0], [0,1,0,0,...] 형태
- 마지막으로 모니터링 항목(Metrics)으로 정확도(acc)를 사용합니다.
note
사용가능한 Metrics 는 기존 측정 항목과 더불어 커스텀 항목으로 다양하게 구현 및 사용할 수 있습니다.
텐서보드 만들기#
먼저 텐서보드를 사용하기 위해서 CAP의 Tensorboard 툴을 이용해 로그 저장 위치를 설정해야합니다.
Tensorboard 메뉴에서 CREATE 버튼을 누른후 아래와 같이 설정합니다.
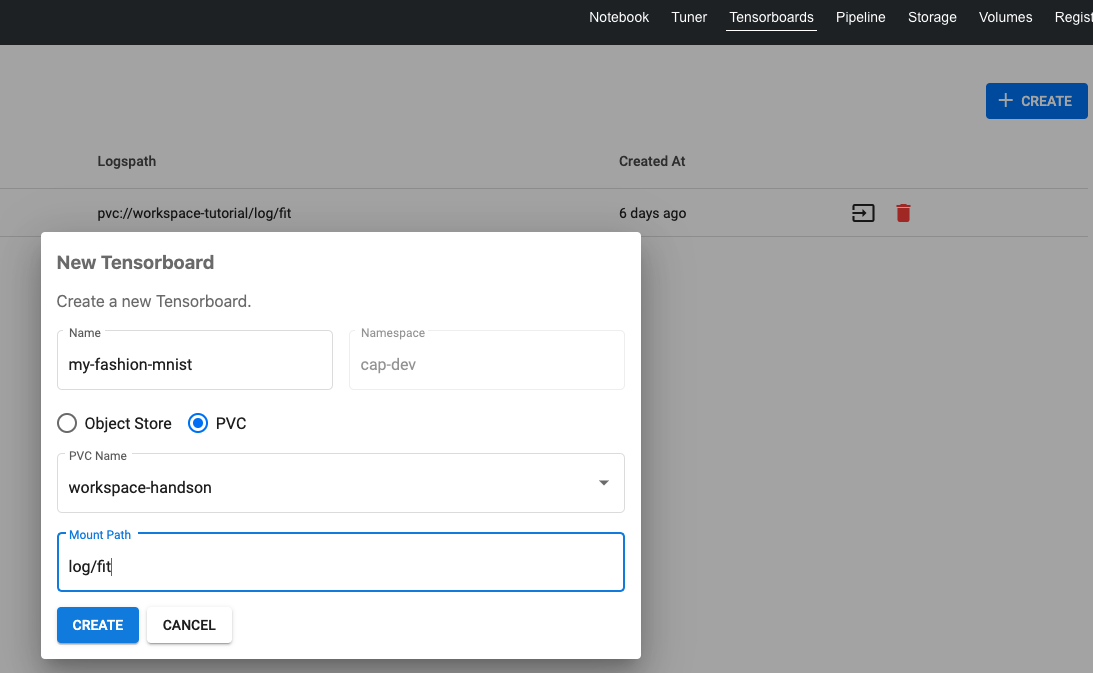
- Name : 텐서보드 이름입니다. 여기선 my-fashion-mnist라고 정하겠습니다.
- Type : Object Store와 PVC를 선택할 수 있습니다. 우리는 노트북에서 사용하는 볼륨(workspace-handson)에 학습 로그가 저장되기 때문에 PVC를 선택합니다.
tip
PVC는 노트북에서 사용하는 볼륨이며 삭제하지 않는 한 Persistent 저장소 입니다.
Object Store는 AWS S3와 같은 클라우드의 오브젝트 스토리지 링크를 적을 수 있습니다.
- PVC Name: 볼륨 이름을 선택합니다. 노트북 볼륨으로 사용하는 workspace-handson으로 지정하겠습니다.
- Mount Path: 로그가 저장될 위치를 정합니다. log/fit으로 경로를 설정하겠습니다.
설정이 완료되면 CREATE 버튼을 눌러 텐서보드를 생성합니다.
아래와 같이 리스트에서 READY 로 확인이 되면 정상적으로 설정이 된 것입니다.

이제 다시 노트북으로 돌아가봅시다.
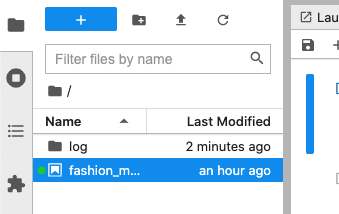
텐서보드 Mount path의 log/fit이 /home/jovyan/log/fit의 경로로 생성된 것을 볼 수 있습니다.
이제 학습 로그를 저장할 준비를 해봅시다.
텐서보드 로그 설정하기#
만든 모델이 keras로 작성되어 있기 때문에 keras callback을 통해서 텐서보드 로그를 출력할 수 있습니다.
텐서보드 로그가 저장될 경로를 먼저 정의합니다.
# fashion_mnist_model.ipynbimport datetimelog_dir = "log/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") print(f"tensorboard log dir : {log_dir}")그리고 tf.keras.callbacks.TensorBoard 를 정의를 해보겠습니다.
# fashion_mnist_model.ipynbtensorboard_cb = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)모델 학습시키기#
- 모델 컴파일과 텐서보드 만들기까지 완료했다면, 이제 모델을 학습시킬 차례입니다.
keras의 fit 함수를 이용하여 총 10번(epochs)의 학습을 진행합니다.
validation_data를 추가하여 학습과 검증을 동시에 진행합니다.
텐서보드를 활용하기 위해 앞서 정의한 콜백함수 tensorboard_cb 를 추가해줍니다.
# fashion_mnist_model.ipynbmodel.fit(x_train, y_train, verbose=1, validation_data=(x_test, y_test), # 검증용 데이터셋 x_test epochs=10, callbacks=[tensorboard_cb]) # callback 함수 추가모델을 학습시키기 위한 전체 코드는 아래와 같습니다. Ctrl-Enter를 눌러 셀을 실행시켜 학습을 시작합시다.
# fashion_mnist_model.ipynb의 전체 코드
import tensorflow as tfimport datetime
mnist = tf.keras.datasets.fashion_mnist(x_train, y_train), (x_test, y_test) = mnist.load_data()
print("x_train shape:", x_train.shape, "y_train shape:", y_train.shape)print("x_test shape:", x_test.shape, "y_test shape:", y_test.shape)
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax')])
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics=['acc'])
log_dir = "log/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") print(f"tensorboard log dir : {log_dir}")tensorboard_cb = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x_train, y_train, verbose=1, validation_data=(x_test, y_test), epochs=10, callbacks=[tensorboard_cb]) 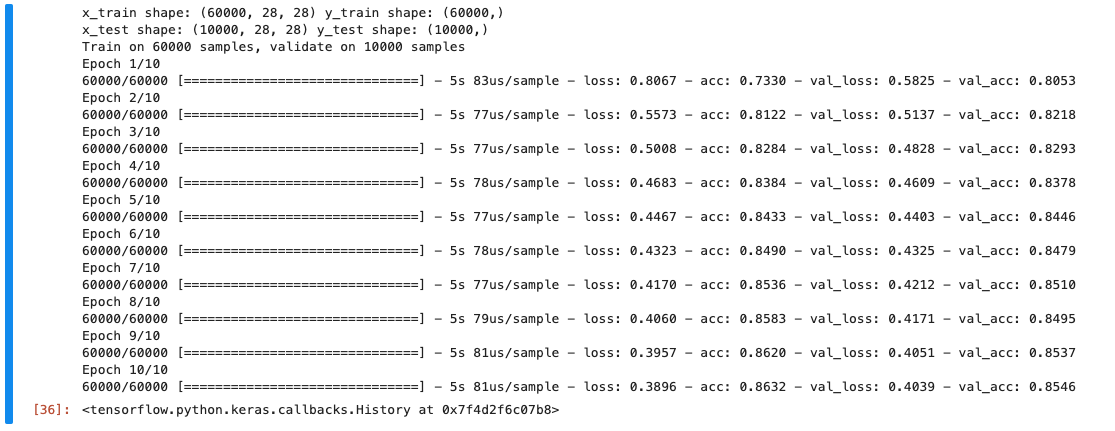
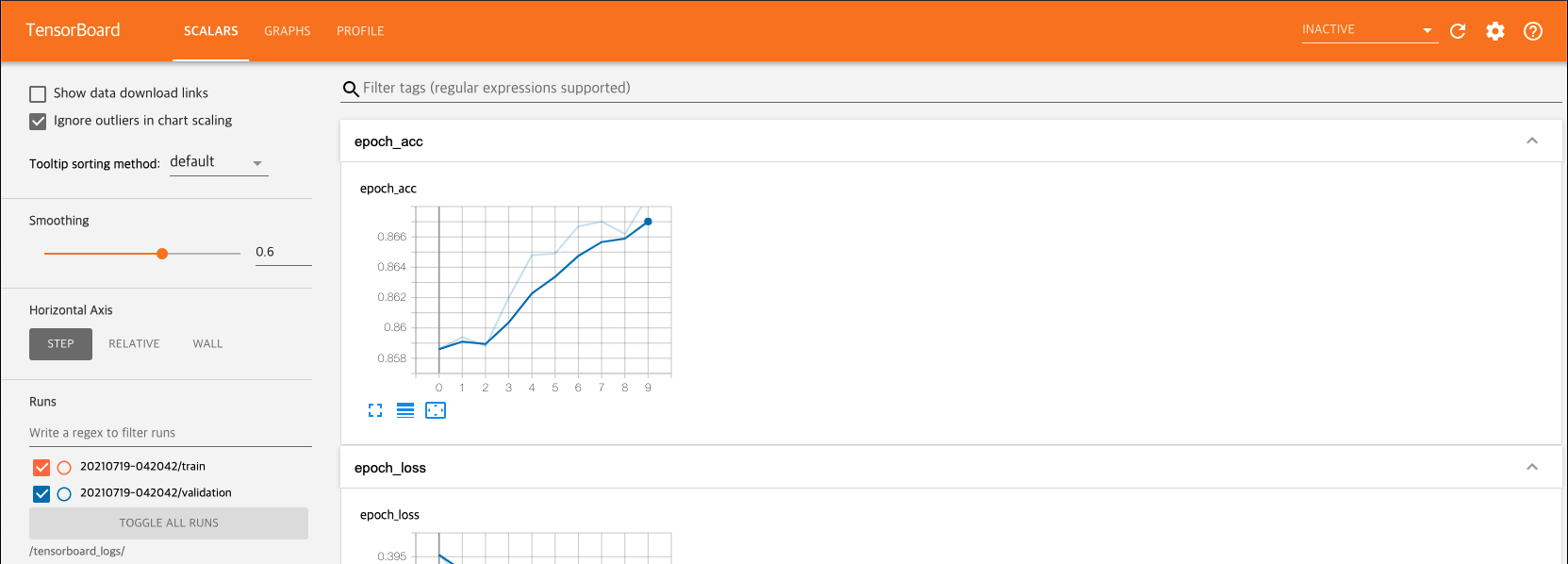
학습결과 10번째 epoch에서 validation_accuracy 가 0.8546을 기록했습니다.
이 모델은 현재 85%의 정확도로 10개의 클래스로 이미지를 가려낼 수 있습니다.
epoch
epoch는 훈련 데이터셋에 포함되어 있는 모든 데이터들이 한번 씩 모델에 들어 온 뒤, weight 값을 갱신하는 주기를 의미합니다. 즉 epoch 값이 10이면 전체 훈련 데이터셋이 10번 신경망을 통과함을 의미합니다.
모델 학습 로그를 Tensorboard로 보기#
10번의 epoch을 거쳐 85퍼센트의 정확도를 가지는 모델을 만들었습니다.
이에 대한 결과를 텐서보드로 확인해봅시다.
위에서 학습을 완료하였다면 log/fit 폴더 하위로 로그가 저장된 것을 확인 할 수 있습니다.
텐서보드 보기#
로그가 저장 된 것을 확인했다면 이제 Tensorboards 메뉴로 가서 텐서보드를 실행해봅시다.
새 창으로 텐서보드가 열리며 학습시킨 모델을 확인할 수 있습니다. 텐서보드의 자세한 사용법은 https://www.tensorflow.org/tensorboard에서 확인하실 수 있습니다.